Stanford CS231A: Computer Vision, From 3D Reconstruction to Recognition
이 포스트는 Stanford CS231A 강의의 열 번째 강의 노트인 “Optimal Estimation”를 정리한 것입니다.
원본 강의 노트: 10-optimal-estimation.pdf
0. 강의 10 한 눈에 보기
이 강의는 “카메라”에서 살짝 벗어나서 시간에 따라 변하는 상태를 추정하는 필터들을 다루는 강의다. 큰 흐름은 이렇게 흘러간다.
- 상태 추정과 POMDP(부분관측 마르코프 결정 과정) 소개
- 베이즈 필터: 아주 일반적인 형태의 “재귀적 상태 추정기”
- 칼만 필터(Kalman Filter): 연속 상태 + 선형 + 가우시안인 경우의 최적 필터
- 확장 칼만 필터(EKF): 비선형 시스템에 칼만 필터 아이디어를 확장한 것
이제 차근차근 스토리처럼 따라가 보겠다.
1. 상태 추정(State Estimation)과 POMDP
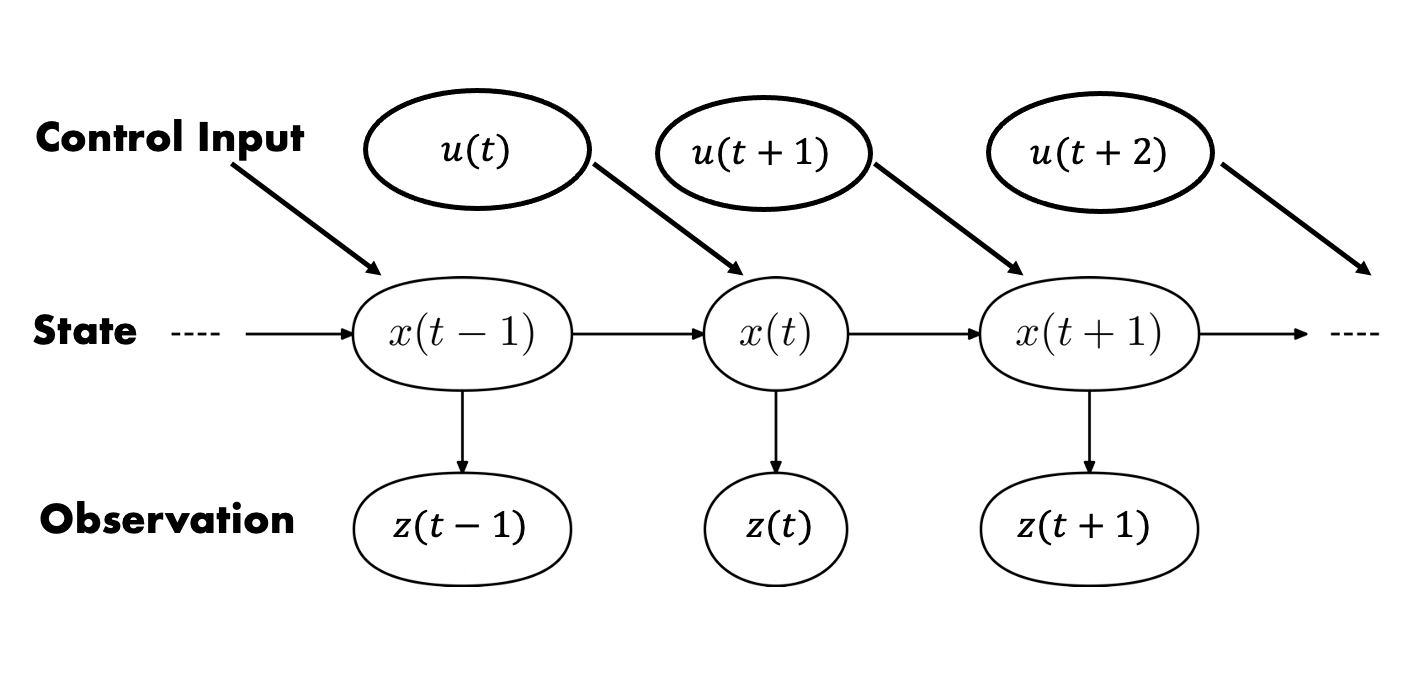
로봇이나 자율주행차를 생각하면 이해가 쉽다. 로봇은 매 순간 “내가 지금 어디에 있고, 속도는 얼마고, 주변 상황은 어떤지” 알고 싶어 한다. 하지만 이 상태 (x_t)는 직접 볼 수 없고, 대신 센서 측정값 (z_t)만 본다. 예를 들어:
- 상태 (x_t): 로봇의 위치, 자세, 속도 벡터 등
- 관측 (z_t): 카메라 이미지, LiDAR 거리, IMU 값 등
- 제어입력 (u_t): 휠에 준 속도 명령, 조향각, 토크 등
강의에서는 이를 부분관측 마르코프 결정과정(POMDP) 그래프로 표현한다.
여기서 핵심 가정이 두 가지다.
-
마르코프 가정(transition model) [ p(x_t \mid x_{0:t-1}, z_{1:t-1}, u_{1:t}) = p(x_t \mid x_{t-1}, u_t) ] 지금 상태는 직전 상태와 지금 입력만 보면 된다는 뜻이다.
-
측정 모델(measurement model) [ p(z_t \mid x_{0:t}, z_{1:t-1}, u_{1:t}) = p(z_t \mid x_t) ] 현재 측정값은 현재 상태만에 의존한다고 가정한다.
우리가 진짜로 알고 싶은 건 “지금 상태가 뭐냐?”이다. 즉 후행분포(posterior)
[ p(x_t \mid z_{1:t}, u_{1:t}) ]
를 시간마다 업데이트하는 것이 목표다. 이 분포를 흔히 belief라 부르고 ( bel_t(x) ) 또는 ( bel(t) )라고 표기한다.
2. 베이즈 필터(Bayes Filter)
2.1 베이즈 관점에서의 재귀적 추정
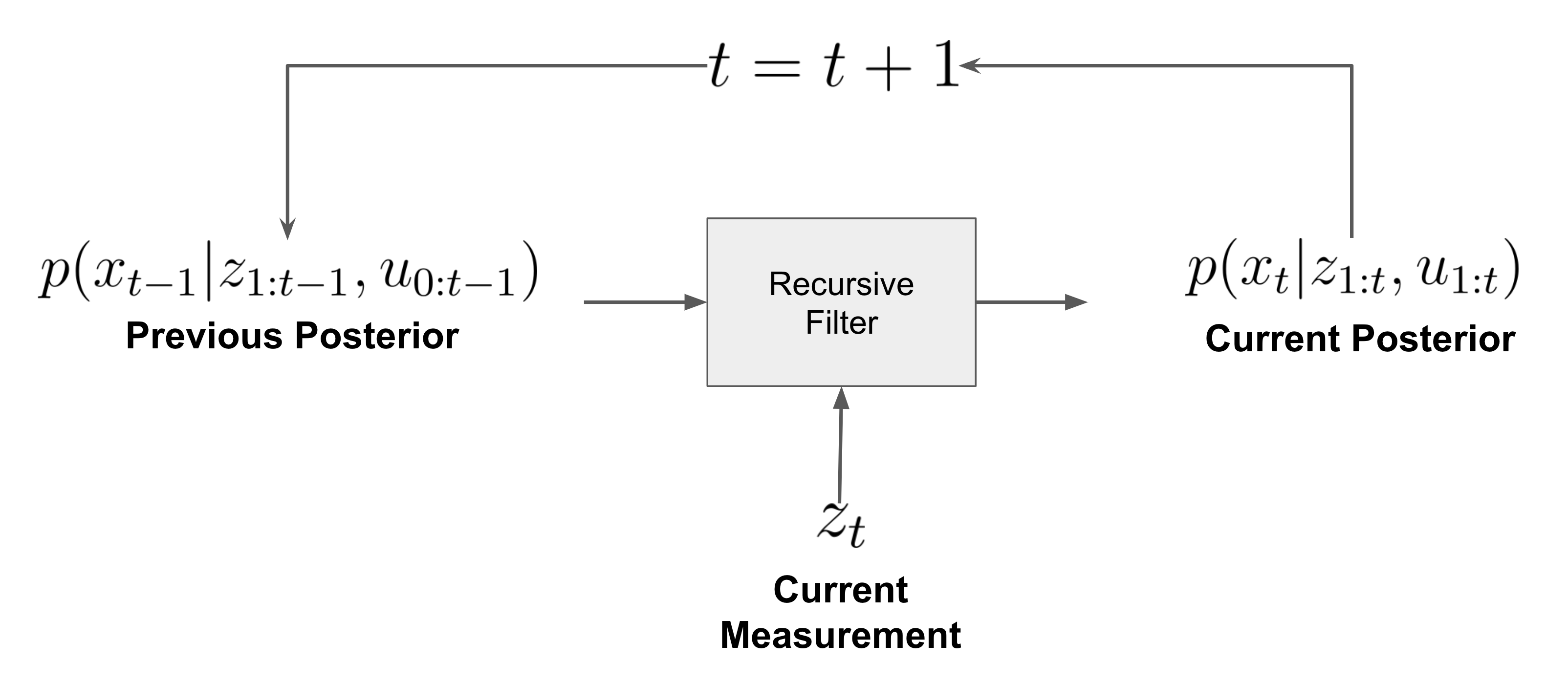
베이즈 필터는 “매 시점마다 이전 belief에 새 관측 하나만 더해서 belief를 업데이트하는” 아주 일반적인 틀이다.
추정하고 싶은 것은 계속 같다.
[ bel_t(x_t) = p(x_t \mid z_{1:t}, u_{1:t}) ]
우리가 원하는 것은 이것을 재귀식으로 쓰는 것이다:
[ p(x_t \mid z_{1:t}, u_{1:t}) = f\big( p(x_{t-1} \mid z_{1:t-1}, u_{1:t-1}), z_t, u_t \big) ]
이를 유도하면 다음과 같이 나온다:
-
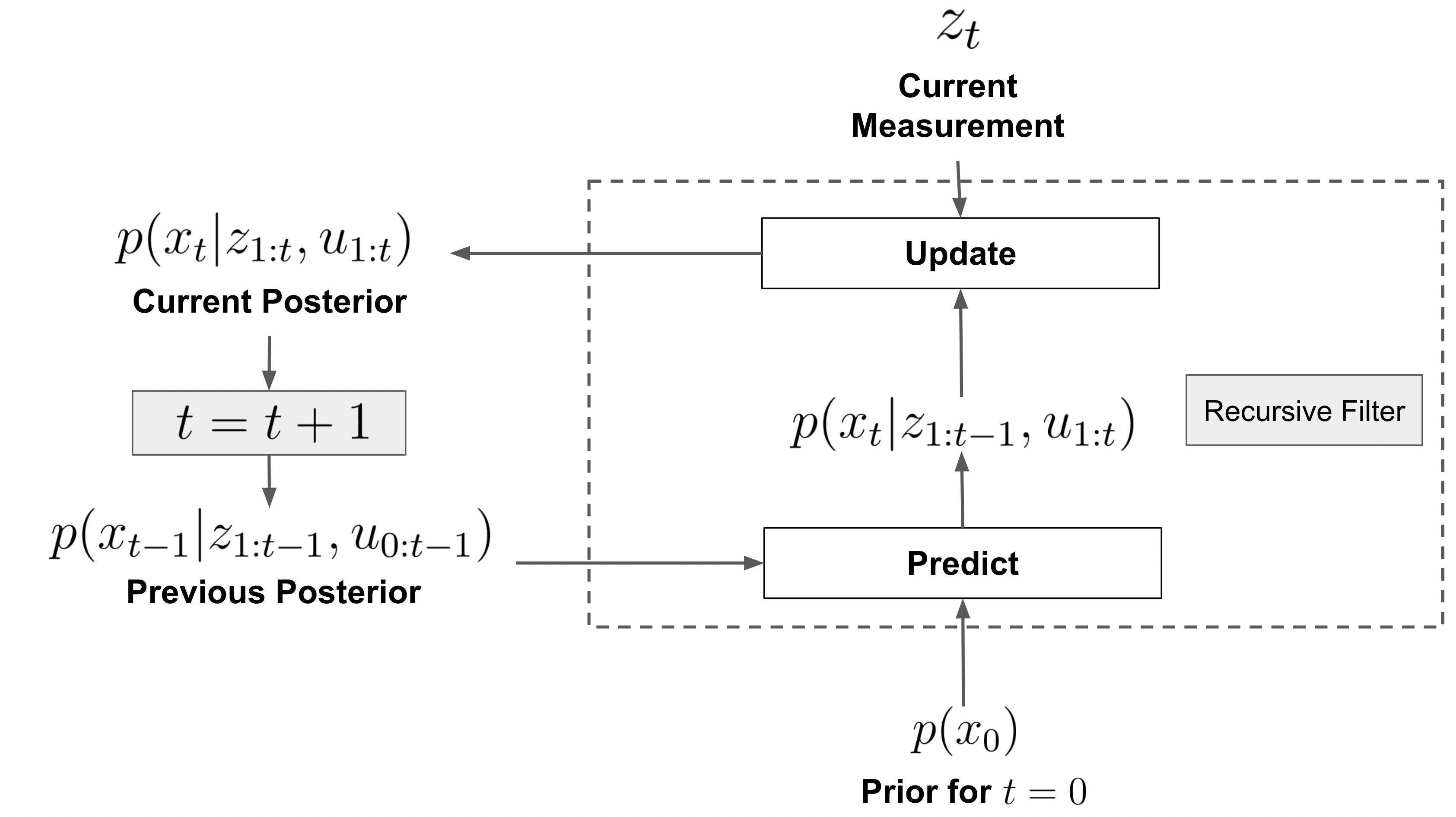
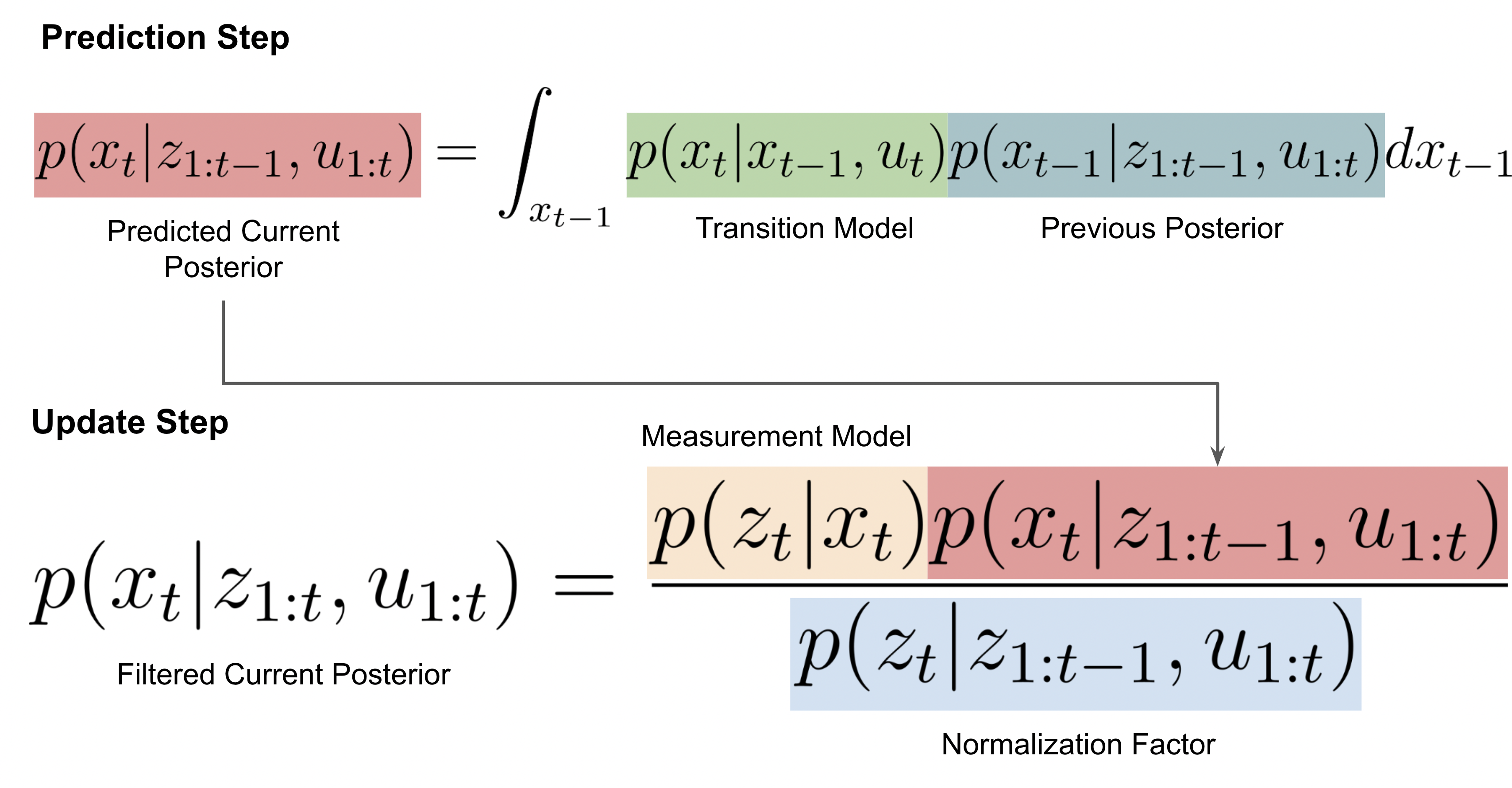
예측(prediction) 단계 [ \underbrace{p(x_t \mid z_{1:t-1}, u_{1:t})}{\text{prior 혹은 predicted belief}} = \int p(x_t \mid x{t-1}, u_t), p(x_{t-1} \mid z_{1:t-1}, u_{1:t-1}) , dx_{t-1} ]
- 이전 posterior에 동역학 모델 (p(x_t \mid x_{t-1}, u_t))를 적용해서 “아직 새로운 측정은 안 본 상태의 belief”를 만든다.
-
업데이트(update) 단계 [ p(x_t \mid z_{1:t}, u_{1:t}) = \eta , p(z_t \mid x_t), p(x_t \mid z_{1:t-1}, u_{1:t}) ] 여기서 (\eta = 1 / p(z_t \mid z_{1:t-1}, u_{1:t}))는 정규화 상수다.
- 측정모델 (p(z_t \mid x_t)) 는 “현재 상태가 (x_t)라면 이런 측정 (z_t)가 나올 확률”을 말한다.
- 예측 prior와 측정 likelihood를 곱해서 새로운 posterior를 얻는다.
이 과정을 그림으로 나타낸 것이 강의 노트의 Bayes filter 다이어그램과 predict/update 블록이다.
2.2 왜 이게 힘든가 (Bayes filter의 한계)
이 식은 매우 일반적이라서, 이론적으로는 모든 확률분포에 적용 가능하다. 하지만 문제가 있다.
- 연속 상태 공간에서는 적분을 매번 계산해야 한다.
- 상태의 전체 분포 (p(x_t))를 모든 x에 대해 다 표현해야 한다.
그래서 실제로는
- 상태공간을 격자로 나누고 bin마다 확률을 저장하는 histogram filter 방식으로 쓸 수도 있지만,
- 차원이 조금만 올라가도 격자 수가 폭발한다.
그래서 “좀 더 구조를 가정하면 효율적인 알고리즘을 만들 수 없을까?”라는 질문에서 칼만 필터가 나온다.
3. 동역학 관점 & 가우시안 분포
3.1 동역학 시스템으로 보기
베이즈 필터에서 등장한 (p(x_t \mid x_{t-1}, u_t)), (p(z_t \mid x_t))를 조금 더 엔지니어링 감각에 맞게 쓰면 다음과 같다.
- 동역학(프로세스) 모델 [ x_t = f(x_{t-1}, u_t) + w_{t-1} ]
- 측정 모델 [ z_t = h(x_t) + v_t ]
여기서
- (w_t): 프로세스 노이즈 (모델링 안 된 외란, 마찰, 바람 등)
- (v_t): 측정 노이즈 (센서 잡음)
둘 다 랜덤변수로 보고, 분포 (D_w, D_v)를 안다고 가정한다.
이 식은 HMM/POMDP 그래프와 완전히 같은 구조를 가진다. 차이가 있다면, 여기서는 연속 상태 벡터와 연속 관측 벡터를 다루는 점이다.
3.2 다변량 가우시안 복습
칼만 필터는 모든 확률분포가 다변량 가우시안이라고 가정한다.
-
(X \in \mathbb{R}^N) 이 다변량 가우시안이면 [ X \sim \mathcal{N}(\mu, \Sigma) ]
- (\mu): 평균 벡터 (\in \mathbb{R}^N)
- (\Sigma): 공분산 행렬 (\in \mathbb{R}^{N\times N}), 양의 반정정부호
PDF는 다음과 같다.
[ p(x) = \frac{1}{\sqrt{(2\pi)^N |\Sigma|}} \exp\left(-\frac{1}{2}(x - \mu)^T \Sigma^{-1} (x - \mu)\right) ]
강의 노트에서는 등고선을 그리면 타원(ellipse)로 보인다고 설명한다.
- 공분산 (\Sigma)의 고유벡터(eigenvectors)가 타원의 축 방향
-
고유값(eigenvalues)이 그 방향으로의 “퍼짐 정도”이다.
- 고유값이 크면 그 방향으로 불확실성이 크다.
- 작으면 그 방향으로 상태를 꽤 정확히 알고 있다는 뜻이다.
또한 (\Sigma)의 off-diagonal 성분은 상태 성분들 사이의 상관관계(correlation)를 나타낸다.
가우시안을 쓰는 가장 큰 이유는:
- (\mu, \Sigma)만 알면 분포 전체를 표현할 수 있고
- 선형 변환 및 합, 조건부 분포도 깔끔한 닫힌형태로 나온다는 점이다.
4. 칼만 필터(Kalman Filter)
4.1 선형-가우시안 시스템
칼만 필터는 다음 두 가지를 가정한다.
- 모든 랜덤 변수(상태, 측정, 노이즈, posterior)가 가우시안
- 동역학 / 측정 모델이 선형
즉,
[ x_t = A_t x_{t-1} + B_t u_t + w_t \tag{14} ] [ z_t = C_t x_t + v_t \tag{15} ]
- (w_t \sim \mathcal{N}(0, Q_t)), (v_t \sim \mathcal{N}(0, R_t)) 이고 각 시점 간에는 상관이 없다고 가정한다.
- 초기 상태도 가우시안 [ x_0 \sim \mathcal{N}(\mu_{0|0}, \Sigma_{0|0}) ] 이라고 둔다.
이렇게 되면, 베이즈 필터에서 다루던 확률분포들은 모두 가우시안이고, 따라서 각 시점마다 분포를 통째로 업데이트할 필요 없이 (\mu)와 (\Sigma)만 업데이트하면 된다.
4.2 예측 단계 (Predict step)
이전 시점의 posterior가
[ x_{t-1} \mid z_{1:t-1}, u_{1:t-1} \sim \mathcal{N}(\mu_{t-1|t-1}, \Sigma_{t-1|t-1}) ]
라고 하자. 그러면 현재 시점의 예측 분포는:
[ \mu_{t|t-1} = A_t \mu_{t-1|t-1} + B_t u_t \tag{16} ] [ \Sigma_{t|t-1} = A_t \Sigma_{t-1|t-1} A_t^T + Q_t \tag{17} ]
- 평균 예측: 이전 평균을 동역학 모델에 넣고, 제어 입력을 더한다. 노이즈 (w_t)는 평균 0이므로 평균에는 영향을 주지 않는다.
- 공분산 예측: 선형변환 (x \mapsto A_t x)를 통해 공분산이 (\text{Cov}(A x) = A \Sigma A^T)로 바뀌고, 프로세스 노이즈의 공분산 (Q_t)를 더한다. → 미래를 “예측”하므로 불확실성이 증가한다.
4.3 업데이트 단계 (Update step)
이제 새로운 측정 (z_t)가 들어온다.
이미 예측한 분포는
[ x_t \mid z_{1:t-1}, u_{1:t} \sim \mathcal{N}(\mu_{t|t-1}, \Sigma_{t|t-1}) ]
이고, 측정 모델은
[ z_t = C_t x_t + v_t, \quad v_t \sim \mathcal{N}(0, R_t) ]
이다. 칼만 필터는 다음과 같이 posterior를 업데이트한다.
[ \mu_{t|t} = \mu_{t|t-1} + K_t (z_t - C_t \mu_{t|t-1}) \tag{18} ] [ \Sigma_{t|t} = \Sigma_{t|t-1} - K_t C_t \Sigma_{t|t-1} \tag{19} ] [ K_t = \Sigma_{t|t-1} C_t^T (C_t \Sigma_{t|t-1} C_t^T + R_t)^{-1} \tag{20} ]
여기서
- (z_t - C_t \mu_{t|t-1}) : measurement residual(innovation), “예측된 측정값”과 “실제 센서 측정값”의 차이다.
- (K_t): 칼만 이득(Kalman gain), 예측과 측정 중 어느 쪽을 얼마나 믿을지를 알려주는 가중치다.
노트에서는 (K_t)를 다시 써서 두 극단을 분석한다.
-
측정 노이즈가 거의 0 ((R_t \to 0))
-
분모의 (C_t \Sigma_{t t-1} C_t^T + R_t \to C_t \Sigma_{t t-1} C_t^T) - 분자와 분모가 거의 같아서, 비율이 1로 가고 (K_t \approx C_t^{-1}) 이 된다.
- 이 경우 측정값을 거의 그대로 믿어서 [ \mu_{t|t} \approx C_t^{-1} z_t ]
- 공분산은 0으로 수렴해 “상태를 확실히 안다”고 본다.
-
-
**프로세스 노이즈가 거의 0 ((\Sigma_{t t-1} \to 0))** - 분자·분모 모두 0에 가까운 부분이지만, 비율은 0으로 가서 (K_t \to 0) 이 된다.
- 즉 측정값을 무시하고 예측만 믿는다.
- 공분산도 변하지 않는다.
현실에서는 둘 다 0이 아니다. 그래서 (K_t)는 항상 0과 1 사이의 “적당한 값”이 되고, 예측과 측정을 적절히 섞어서 추정을 수행한다.
4.4 분포 관점에서 보기
노트의 그림 6은 2차원 상태에서 세 개의 타원을 그려놓는다.
-
오렌지 타원: 예측된 측정 분포 ( \mathcal{N}(C_t \mu_{t t-1}, C_t \Sigma_{t t-1} C_t^T)) - 파란 타원: 실제 측정의 분포 ( \mathcal{N}(z_t, R_t))
-
초록 타원: 둘을 곱한 결과인 업데이트된 posterior ( \mathcal{N}(\mu_{t t}, \Sigma_{t t}))
두 분포를 곱하면 겹치는 부분에서 확률이 커지고, 이 부분이 다시 하나의 가우시안 타원으로 표현된다.
재미있는 점은,
- 예측 단계: 공분산이 커져서 타원이 커진다 (불확실성 증가).
- 업데이트 단계: 측정을 반영해서 타원이 줄어든다 (불확실성 감소).
이 과정을 계속 반복하면 공분산이 점점 줄어들다가 어느 수준에서 수렴한다.
5. 확장 칼만 필터(Extended Kalman Filter, EKF)
현실 시스템은 대부분 비선형이다.
예를 들면,
- 상태가 로봇의 위치/자세, 관측이 카메라 픽셀 좌표라면 투영식 (h(x))는 분명히 선형이 아니다.
비선형 동역학:
[ x_t = f(x_{t-1}, u_t) + w_t ] [ z_t = g(x_t) + v_t ]
를 그대로 사용하면, 가우시안 분포가 비선형 함수에 의해 통과하면서 비가우시안으로 바뀐다. 이 경우 앞서 썼던 깔끔한 칼만 필터 식을 그대로 쓸 수 없다.
EKF의 아이디어는 단순하다.
“비선형 함수를 현재 평균 주변에서 1차 테일러 근사(선형화) 해서, 그 순간만큼은 선형-가우시안처럼 취급하자”
즉, 각 시점 t에서
-
(f(x, u))를 (x = \mu_{t-1 t-1}) 주변에서 -
(g(x))를 (x = \mu_{t t-1}) 주변에서
선형화한다.
5.1 EKF 공식
선형화 후의 Jacobian은 다음과 같다.
[ A_t = \left. \frac{\partial f(x_t, u_t)}{\partial x_t} \right|{x_t = \mu{t-1|t-1}} \tag{27} ] [ C_t = \left. \frac{\partial g(x_t, u_t)}{\partial x_t} \right|{x_t = \mu{t|t-1}} \tag{28} ]
이걸 이용하면 EKF의 예측/업데이트 식은 칼만 필터와 형태가 거의 같다.
-
Predict [ \mu_{t|t-1} = f(\mu_{t-1|t-1}, u_t) \tag{22} ] [ \Sigma_{t|t-1} = A_{t-1} \Sigma_{t-1|t-1} A_{t-1}^T + Q_{t-1} \tag{23} ]
-
Update [ \mu_{t|t} = \mu_{t|t-1} + K_t (z_t - g(\mu_{t|t-1})) \tag{24} ] [ \Sigma_{t|t} = \Sigma_{t|t-1} - K_t C_t \Sigma_{t|t-1} \tag{25} ] [ K_t = \Sigma_{t|t-1} C_t^T \big(C_t \Sigma_{t|t-1} C_t^T + R_t\big)^{-1} \tag{26} ]
따라서 EKF는
- 현재 추정치 주변에서 모델을 선형화하고
- 그 선형 모델에 칼만 필터를 적용하는 방식으로 작동한다.
비선형성이 심하면 근사가 잘 안 맞을 수 있다는 한계는 있지만, 로봇 공학, SLAM, 비전 기반 로컬라이제이션 등에서 매우 널리 쓰인다.
6. 이 강의에서 꼭 가져가야 할 직관
-
상태 추정은 “숨은 상태”를 확률적으로 추적하는 문제다.
- belief (p(x_t \mid z_{1:t}, u_{1:t}))를 관리하는 문제라고 생각하면 된다.
-
베이즈 필터는 가장 일반적인 틀이고,
- 새로운 관측과 이전 belief를 곱해서 posterior를 만드는 구조다.
-
칼만 필터는 이를 선형-가우시안에 특화시켜
- (\mu, \Sigma) 만 업데이트하는 효율적인 알고리즘이다.
- 예측으로 불확실성이 커지고,
- 측정으로 다시 줄어들면서 점점 수렴한다.
-
EKF는 “비선형 시스템을 매 시점마다 선형 근사해서” 칼만 필터를 적용하는 버전이다.
이제 실제로 간단한 코드로 한 번 감을 잡아보자.
7. 파이썬으로 1D 칼만 필터 실습 코드 (NumPy)
가장 단순한 예: 1D 위치 + 속도 상태를 갖는 객체가 일정 속도로 움직이고, 우리는 위치만 노이즈 섞인 값으로 측정한다고 하자.
- 상태: (x = [\text{position}, \text{velocity}]^T)
- 입력 없음 ((u_t = 0))
- 시간 간격: (\Delta t)
선형 모델은 다음과 같다.
[
x_t =
\begin{bmatrix}
1 & \Delta t
0 & 1
\end{bmatrix}
x_{t-1} + w_t
]
[ z_t = \begin{bmatrix} 1 & 0 \end{bmatrix} x_t + v_t ]
아래는 그 구현 예시다.
import numpy as np
import matplotlib.pyplot as plt
dt = 0.1 # time step
# 상태 전이 행렬 A, 관측 행렬 H
A = np.array([[1, dt],
[0, 1]], dtype=float)
H = np.array([[1, 0]], dtype=float)
# 프로세스 노이즈, 측정 노이즈 공분산
Q = np.array([[1e-4, 0],
[0, 1e-4]], dtype=float)
R = np.array([[0.5**2]], dtype=float) # 측정 표준편차 0.5
# 초기 상태 추정
mu = np.array([[0.0],
[1.0]]) # 초기 위치 0, 속도 1
Sigma = np.eye(2)
# 실제 궤적 / 측정값 생성
T = 100
true_states = []
measurements = []
x_true = np.array([[0.0],
[1.0]])
for _ in range(T):
# 진짜 동역학 (여기서는 noise도 넣어보자)
process_noise = np.random.multivariate_normal(mean=[0, 0], cov=Q).reshape(2, 1)
x_true = A @ x_true + process_noise
true_states.append(x_true.copy())
# 측정 (위치만)
meas_noise = np.random.normal(loc=0.0, scale=np.sqrt(R[0, 0]))
z = H @ x_true + meas_noise
measurements.append(z.item())
true_states = np.hstack(true_states) # shape (2, T)
measurements = np.array(measurements)
# 칼만 필터 루프
estimates = []
for t in range(T):
# === Predict ===
mu = A @ mu # (16)
Sigma = A @ Sigma @ A.T + Q # (17)
# === Update ===
z = np.array([[measurements[t]]])
y = z - H @ mu # innovation
S = H @ Sigma @ H.T + R # innovation covariance
K = Sigma @ H.T @ np.linalg.inv(S) # (20)
mu = mu + K @ y # (18)
Sigma = Sigma - K @ H @ Sigma # (19)
estimates.append(mu.copy())
estimates = np.hstack(estimates) # shape (2, T)
# 시각화
plt.figure()
plt.plot(true_states[0], label="true position")
plt.plot(measurements, ".", alpha=0.4, label="measurements")
plt.plot(estimates[0], label="KF estimate")
plt.legend()
plt.xlabel("time step")
plt.ylabel("position")
plt.title("1D Position Tracking with Kalman Filter")
plt.show()
이 스크립트를 실행하면,
- 파란 선: 실제 위치
- 점: 노이즈 섞인 측정
- 주황/초록 선: 칼만 필터가 추정한 위치
를 볼 수 있다. 측정보다 훨씬 매끈하고, 실제 궤적에 잘 따라붙는 것을 볼 수 있다.
8. OpenCV 기반 2D 칼만 필터 예제 (이미지 좌표 트래킹)
OpenCV에는 cv::KalmanFilter / cv2.KalmanFilter 클래스가 있어서
2D 점을 추정하는 데 바로 쓸 수 있다.
(아래 코드는 Python + OpenCV 기준이다.)
import cv2
import numpy as np
# 상태: [x, y, vx, vy]^T
stateSize = 4
measSize = 2
ctrlSize = 0
kf = cv2.KalmanFilter(stateSize, measSize, ctrlSize)
dt = 0.1
# 상태 전이 행렬 A
kf.transitionMatrix = np.array([
[1, 0, dt, 0],
[0, 1, 0, dt],
[0, 0, 1, 0],
[0, 0, 0, 1]
], np.float32)
# 측정 행렬 H (위치만 관측)
kf.measurementMatrix = np.array([
[1, 0, 0, 0],
[0, 1, 0, 0]
], np.float32)
# 프로세스/측정 노이즈 공분산
kf.processNoiseCov = np.eye(stateSize, dtype=np.float32) * 1e-4
kf.measurementNoiseCov = np.eye(measSize, dtype=np.float32) * 1e-1
kf.errorCovPost = np.eye(stateSize, dtype=np.float32)
# 초기 상태
kf.statePost = np.array([[100.],
[100.],
[1.],
[0.]], np.float32)
# 가짜 측정값 시퀀스를 만들어보자 (직선 + 노이즈)
T = 100
measurements = []
true_positions = []
pos = np.array([100., 100.])
vel = np.array([1., 0.5])
for _ in range(T):
pos = pos + vel * dt
true_positions.append(pos.copy())
noise = np.random.normal(0, 2.0, size=2)
meas = pos + noise
measurements.append(meas)
# KF 루프
est_positions = []
for i in range(T):
# 예측
pred = kf.predict()
# 측정 업데이트
z = np.array([[measurements[i][0]],
[measurements[i][1]]], np.float32)
kf.correct(z)
est_positions.append(pred[:2].ravel())
true_positions = np.array(true_positions)
measurements = np.array(measurements)
est_positions = np.array(est_positions)
# 간단 시각화 (matplotlib)
import matplotlib.pyplot as plt
plt.figure()
plt.scatter(true_positions[:,0], true_positions[:,1], s=5, label="true")
plt.scatter(measurements[:,0], measurements[:,1], s=5, alpha=0.3, label="meas")
plt.plot(est_positions[:,0], est_positions[:,1], label="KF estimate")
plt.axis("equal")
plt.legend()
plt.title("2D Tracking with OpenCV KalmanFilter")
plt.show()
이 코드는
- 가상의 2D 점이 직선으로 움직이고
- 각 시점마다 노이즈 섞인 좌표를 관측하는 상황에서
- OpenCV 칼만 필터가 점의 궤적을 부드럽게 추정하는 예시다.
1. 서론 (Introduction)
최적 추정(Optimal Estimation)은 노이즈가 있는 관측으로부터 시스템의 상태를 추정하는 기술입니다. 로봇 공학, 자율 주행, 추적 등에서 핵심적인 역할을 합니다.
2. 상태 추정 (State Estimation)
2.1. 상태 공간 모델
시스템의 상태를 다음과 같이 모델링합니다:
\[x_t = f(x_{t-1}, u_t, w_t)\] \[z_t = h(x_t, v_t)\]여기서:
- $x_t$: 시간 $t$에서의 상태
- $u_t$: 제어 입력
- $z_t$: 관측
- $w_t, v_t$: 프로세스 및 관측 노이즈
2.2. 추정 문제
과거 관측 $z_{1:t}$로부터 현재 상태 $x_t$를 추정하는 문제입니다.
3. 베이지안 필터 (Bayesian Filter)
3.1. 조건부 확률 복습
베이지안 필터는 조건부 확률을 기반으로 합니다:
-
사전 확률 (Prior): $P(x_t z_{1:t-1})$ -
사후 확률 (Posterior): $P(x_t z_{1:t})$ -
우도 (Likelihood): $P(z_t x_t)$
3.2. 베이지안 필터 유도
베이즈 정리를 사용하여 사후 확률을 계산합니다:
\[P(x_t | z_{1:t}) = \frac{P(z_t | x_t) P(x_t | z_{1:t-1})}{P(z_t | z_{1:t-1})}\]3.3. 예측 단계 (Prediction)
이전 상태로부터 현재 상태를 예측합니다:
\[P(x_t | z_{1:t-1}) = \int P(x_t | x_{t-1}) P(x_{t-1} | z_{1:t-1}) dx_{t-1}\]3.4. 업데이트 단계 (Update)
관측을 통하여 상태를 업데이트합니다:
\[P(x_t | z_{1:t}) \propto P(z_t | x_t) P(x_t | z_{1:t-1})\]4. 칼만 필터 (Kalman Filter)
4.1. 선형 칼만 필터
선형 시스템과 가우시안 노이즈를 가정합니다:
\[x_t = A x_{t-1} + B u_t + w_t\] \[z_t = C x_t + v_t\]여기서 $w_t \sim \mathcal{N}(0, Q)$, $v_t \sim \mathcal{N}(0, R)$입니다.
4.2. 칼만 필터 알고리즘
- 예측 (Predict):
-
상태 예측: $\hat{x}_{t t-1} = A \hat{x}_{t-1 t-1} + B u_t$ -
공분산 예측: $P_{t t-1} = A P_{t-1 t-1} A^T + Q$
-
- 업데이트 (Update):
-
칼만 gain: $K_t = P_{t t-1} C^T (C P_{t t-1} C^T + R)^{-1}$ -
상태 업데이트: $\hat{x}_{t t} = \hat{x}_{t t-1} + K_t (z_t - C \hat{x}_{t t-1})$ -
공분산 업데이트: $P_{t t} = (I - K_t C) P_{t t-1}$
-
4.3. 확장 칼만 필터 (Extended Kalman Filter, EKF)
비선형 시스템을 선형화하여 칼만 필터를 적용합니다.
5. 파티클 필터 (Particle Filter)
5.1. 파티클 필터의 개념
비선형, 비가우시안 시스템을 처리하기 위한 몬테카를로 방법입니다.
5.2. 파티클 필터 알고리즘
- 샘플링: 사전 분포에서 파티클 샘플링
- 가중치 계산: 관측에 기반하여 가중치 계산
- 리샘플링: 가중치에 따라 파티클 재샘플링
6. 응용 분야 (Applications)
최적 추정은 다음과 같은 분야에서 활용됩니다:
- 로봇 공학: 위치 추정 및 추적
- 자율 주행: 차량 위치 및 속도 추정
- 객체 추적: 비디오에서 객체 추적
- 센서 융합: 여러 센서 데이터 통합
- SLAM (Simultaneous Localization and Mapping): 동시 위치 추정 및 맵핑
요약
이 강의에서는 다음과 같은 내용을 다뤘습니다:
- 상태 추정: 노이즈가 있는 관측으로부터 상태 추정
- 베이지안 필터: 확률론적 상태 추정 프레임워크
- 칼만 필터: 선형 시스템을 위한 최적 필터
- 파티클 필터: 비선형 시스템을 위한 몬테카를로 방법
최적 추정은 불확실성이 있는 환경에서 시스템 상태를 추정하는 핵심 기술입니다.