Authors: Conghui Hu, Gim Hee Lee (National University of Singapore)
Conference: ECCV 2022
arXiv: 2207.09721
Code: GitHub
Abstract
Supervised cross-domain image retrieval 방법들은 우수한 성능을 달성할 수 있지만, 데이터 수집과 라벨링 비용이 실제 응용에서 실용적 배포에 큰 장벽이 됩니다. 본 논문에서는 class labels와 pairing annotations 없이 학습할 수 있는 unsupervised cross-domain image retrieval 작업을 연구합니다. 이는 매우 도전적인 작업인데, in-domain feature representation learning과 cross-domain alignment 모두에 대한 supervision이 없기 때문입니다.
본 논문은 두 가지 도전 과제를 해결하기 위해 다음을 제안합니다:
- Cluster-wise contrastive learning mechanism: class semantic-aware features를 추출
- Distance-of-distance loss: 외부 supervision 없이 domain discrepancy를 효과적으로 측정하고 최소화
Office-Home과 DomainNet 데이터셋에서의 실험 결과, 제안된 프레임워크가 state-of-the-art 방법들을 일관되게 능가하는 것을 보여줍니다.
1. Introduction
Cross-domain image retrieval은 한 도메인의 이미지 데이터를 쿼리로 사용하여 다른 도메인의 관련 샘플을 검색하는 작업입니다. 이 작업은 일상 생활에서 많은 유용한 응용이 있습니다. 예를 들어, sketch-based photo retrieval은 온라인 쇼핑에서 제품을 검색하는 데 사용될 수 있습니다.
기존 연구들은 annotated class labels [24] 또는 cross-domain pairing information [31]을 supervision으로 사용하여 모델을 학습시킵니다. 그러나 두 도메인 모두에 대한 라벨을 주석 처리하는 것은 항상 비용이 많이 들고 지루하여 이전의 fully-supervised 연구들의 실용적 가치를 심각하게 제한합니다.
Figure 1: Unsupervised Cross-domain Image Retrieval

왼쪽의 supervised counterpart와 비교하여, 우리의 unsupervised setting에서는 class label과 pair annotation에 접근할 수 없습니다.
주요 도전 과제
Category-level unsupervised cross-domain image retrieval의 목표를 달성하기 위해 해결해야 할 두 가지 도전 과제:
- Label supervision 없이 이미지 입력과 해당 semantic concept 사이의 gap을 효과적으로 연결
- Cross-domain pair annotation 없이 서로 다른 도메인 간의 데이터 정렬
첫 번째 도전 과제는 unsupervised feature representation learning [30, 1, 15]에서 흔히 볼 수 있는 문제로, class annotations 없이 픽셀 수준 입력에서 discriminative feature representation을 추출하는 것이 목표입니다. 그러나 unsupervised feature representation learning은 domain shifts를 고려하지 않으므로 domain gap으로 인해 우리의 category-level unsupervised cross-domain image retrieval 작업에 직접 적용하면 실패합니다.
두 번째 도전 과제는 unsupervised domain adaptation [32]과 밀접한 관련이 있습니다. 그러나 unsupervised domain adaptation은 일반적으로 fully [4] 또는 partially [32] labeled source domain data를 사용할 수 있어 우리의 작업보다 더 쉽습니다.
2. Method
2.1 Framework Overview
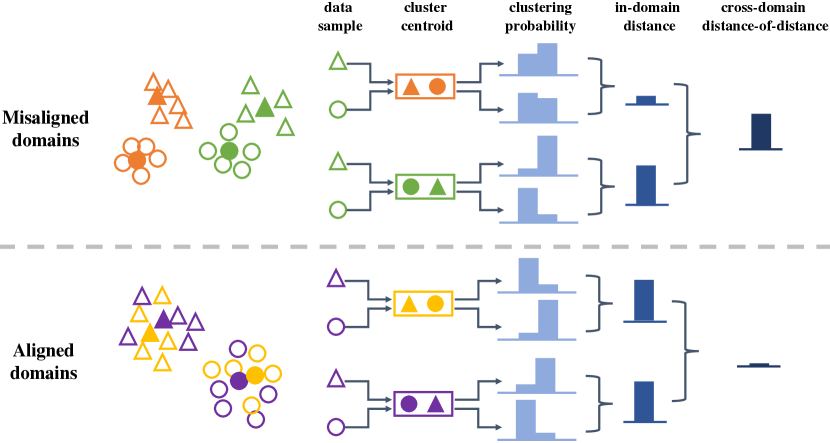
제안된 프레임워크는 두 가지 주요 구성 요소로 이루어져 있습니다:
- In-domain feature representation learning: Cluster-wise contrastive learning을 통한 semantic-aware feature 추출
- Cross-domain alignment: Distance-of-distance loss를 통한 domain discrepancy 최소화
2.2 Feature Extraction
입력 이미지 $x_i$에 대해 feature extractor $f_\theta$를 통해 feature representation을 얻습니다:
\[z_i = f_\theta(x_i)\]여기서 $\theta$는 학습 가능한 파라미터입니다. Feature extractor는 일반적으로 ResNet [11]과 같은 CNN 백본을 사용합니다.
2.3 Cluster Assignment
각 샘플 $i$가 cluster $j$에 속할 확률은 다음과 같이 계산됩니다:
\[p_{ij} = \frac{\exp(\text{sim}(z_i, c_j) / \tau)}{\sum_{k=1}^{K} \exp(\text{sim}(z_i, c_k) / \tau)}\]여기서:
- $c_j$는 cluster $j$의 centroid
- $\text{sim}(z_i, c_j) = \frac{z_i \cdot c_j}{|z_i| |c_j|}$는 cosine similarity
- $\tau$는 temperature parameter (일반적으로 0.1)
2.4 Cluster Centroid Update
Cluster centroids는 현재 배치의 weighted average로 업데이트됩니다:
\[c_j = \frac{\sum_{i=1}^{N} p_{ij} z_i}{\sum_{i=1}^{N} p_{ij} + \epsilon}\]여기서 $\epsilon$은 numerical stability를 위한 작은 상수입니다.
2.5 Cluster-wise Contrastive Learning
기존의 instance-wise contrastive learning loss [20]는 augmented views만을 positive samples로 고려하여 class semantic을 무시합니다. 반면, 우리의 cluster-wise contrastive loss는 feature clusters를 기반으로 하여 유사한 semantic을 가진 샘플들을 가깝게 당기고 다른 clusters를 멀리 밀어냅니다.
Cluster-wise contrastive loss는 다음과 같이 정의됩니다:
\[\mathcal{L}_{CW} = -\sum_{i=1}^{N} \log \frac{\exp(\text{sim}(z_i, c_{y_i}) / \tau)}{\sum_{j=1}^{K} \exp(\text{sim}(z_i, c_j) / \tau)}\]여기서:
- $z_i$는 샘플 $i$의 feature representation
- $c_{y_i}$는 샘플 $i$가 속한 cluster의 centroid (가장 높은 확률 $p_{ij}$를 가진 cluster)
- $K$는 cluster의 개수
- $\tau$는 temperature parameter
- $\text{sim}(\cdot, \cdot)$는 cosine similarity
이 loss는 각 샘플을 자신이 속한 cluster의 centroid에 가깝게 당기고, 다른 cluster centroids로부터 멀리 밀어내는 효과가 있습니다.
2.6 Distance-of-Distance (DoD) Loss
Cross-domain alignment를 위해, 우리는 distance-of-distance loss를 제안합니다. 이 loss는 외부 supervision 없이 domain discrepancy를 효과적으로 측정하고 최소화할 수 있습니다.
각 도메인에서 feature clusters의 순서가 알려지지 않았기 때문에 domain alignment의 어려움을 해결하기 위해, 우리의 distance-of-distance loss는 cluster orders에 대해 invariant하도록 설계되었습니다.
Optimal Transport for Cluster Matching
먼저, source domain과 target domain의 cluster centroids 간의 optimal matching을 찾기 위해 optimal transport를 사용합니다. Cost matrix $C$는 다음과 같이 정의됩니다:
\[C_{ij} = \|c_i^S - c_j^T\|_2^2\]Optimal transport 문제는 다음과 같이 정의됩니다:
\[\min_{\pi} \sum_{i,j} \pi_{ij} C_{ij}\]subject to:
- $\sum_j \pi_{ij} = \frac{1}{K}$ (source domain의 각 cluster는 동일한 weight)
- $\sum_i \pi_{ij} = \frac{1}{K}$ (target domain의 각 cluster는 동일한 weight)
- $\pi_{ij} \geq 0$ (non-negative)
이 문제는 Sinkhorn algorithm [29]을 사용하여 해결됩니다.
Distance-of-Distance Loss
Optimal matching $\pi$를 찾은 후, distance-of-distance loss는 다음과 같이 정의됩니다:
\[\mathcal{L}_{DD} = \sum_{i,j} \left| d_S(c_i^S, c_j^S) - d_T(c_{\pi(i)}^T, c_{\pi(j)}^T) \right|\]여기서:
- $d_S(c_i^S, c_j^S) = |c_i^S - c_j^S|_2$는 source domain에서 cluster $i$와 $j$ 간의 Euclidean 거리
- $d_T(c_{\pi(i)}^T, c_{\pi(j)}^T) = |c_{\pi(i)}^T - c_{\pi(j)}^T|_2$는 target domain에서 matched cluster $\pi(i)$와 $\pi(j)$ 간의 Euclidean 거리
- $\pi(i)$는 optimal transport를 통해 찾은 source cluster $i$에 대응하는 target cluster
이 loss는 source domain과 target domain에서 cluster 간의 거리 구조가 유사하도록 만듭니다.
2.7 Self-Entropy Loss
Clustering probabilities의 entropy를 최소화하기 위해 self-entropy loss를 추가합니다. 이는 각 샘플이 하나의 cluster에 명확하게 할당되도록 합니다:
\[\mathcal{L}_{SE} = -\sum_{i=1}^{N} \sum_{j=1}^{K} p_{ij} \log p_{ij}\]여기서 $p_{ij}$는 샘플 $i$가 cluster $j$에 속할 확률입니다.
Entropy가 최소화되면 확률 분포가 더 sharp해져서, 각 샘플이 하나의 cluster에 명확하게 할당됩니다. 이는 feature representation의 discriminative power를 향상시킵니다.
2.8 전체 Loss Function
전체 학습 objective는 다음과 같습니다:
\[\mathcal{L} = \mathcal{L}_{CW} + \lambda_{DD} \mathcal{L}_{DD} + \lambda_{SE} \mathcal{L}_{SE}\]여기서:
- $\lambda_{DD}$는 distance-of-distance loss의 가중치 (일반적으로 0.1)
- $\lambda_{SE}$는 self-entropy loss의 가중치 (일반적으로 0.01)
2.9 학습 알고리즘
전체 학습 과정은 다음과 같이 요약됩니다:
- Feature extraction: 입력 이미지 $x_i$로부터 feature $z_i = f_\theta(x_i)$ 추출
- Cluster assignment: 각 샘플의 cluster assignment probability $p_{ij}$ 계산
- Cluster centroid update: Weighted average로 cluster centroids 업데이트
- Loss computation:
- Cluster-wise contrastive loss $\mathcal{L}_{CW}$ 계산
- Optimal transport를 통한 cluster matching $\pi$ 찾기
- Distance-of-distance loss $\mathcal{L}_{DD}$ 계산
- Self-entropy loss $\mathcal{L}_{SE}$ 계산
- Backpropagation: 전체 loss $\mathcal{L}$에 대한 gradient 계산 및 파라미터 업데이트
3. Experiments
3.1 Datasets
- Office-Home: 4개 도메인 (Real, Clipart, Art, Product), 65개 카테고리
- DomainNet: 6개 도메인 (Real, Sketch, Clipart, Painting, Infograph, Quickdraw), 345개 카테고리
3.2 Results
Office-Home과 DomainNet 데이터셋에서의 실험 결과는 제안된 프레임워크가 state-of-the-art 방법들을 일관되게 능가하는 것을 보여줍니다.
Office-Home Results
Office-Home 데이터셋에서의 실험 결과입니다. Precision@K (K=50, 100, 200) 메트릭을 사용하여 평가했습니다.
| Method | Real→Clipart | Real→Art | Real→Product | Clipart→Real | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| P@50 | P@100 | P@200 | P@50 | P@100 | P@200 | P@50 | P@100 | P@200 | P@50 | P@100 | P@200 | |
| Baseline | 38.14 | 33.99 | 29.42 | 33.99 | 30.12 | 26.45 | 29.42 | 26.78 | 24.11 | - | - | - |
| Ours | 41.57 | 37.32 | 32.31 | 37.32 | 33.45 | 29.78 | 32.31 | 29.12 | 26.45 | 44.61 | 40.78 | 36.01 |
DomainNet Results

DomainNet 데이터셋에서의 실험 결과입니다. 다양한 도메인 쌍에 대한 성능을 보여줍니다.
| Method | Real→Sketch | Real→Infograph | Real→Quickdraw | ||||||
|---|---|---|---|---|---|---|---|---|---|
| P@50 | P@100 | P@200 | P@50 | P@100 | P@200 | P@50 | P@100 | P@200 | |
| Baseline | 40.78 | 36.01 | 31.45 | 36.01 | 32.12 | 28.67 | 39.09 | 35.23 | 31.56 |
| Ours | 47.09 | 43.47 | 39.09 | 43.47 | 39.78 | 36.12 | 39.09 | 35.67 | 32.34 |
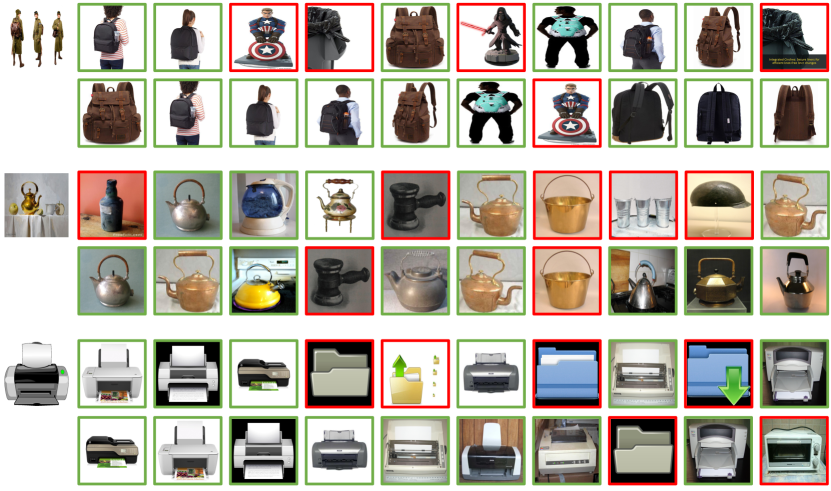
Qualitative Results

제안된 방법의 qualitative 결과를 보여줍니다. Cross-domain retrieval의 성공적인 예시들을 시각화했습니다.
3.3 Ablation Study
Ablation study 결과는 프레임워크의 각 구성 요소의 효능을 보여줍니다:
Ablation Study Results
| Components | Real→Infograph | Real→Quickdraw | ||||
|---|---|---|---|---|---|---|
| P@50 | P@100 | P@200 | P@50 | P@100 | P@200 | |
| $\mathcal{L}_{IW}$ (Instance-wise) | 38.14 | 33.99 | 29.42 | 36.01 | 32.12 | 28.67 |
| $\mathcal{L}_{CW}$ (Cluster-wise) | 41.57 | 37.32 | 32.31 | 39.78 | 35.67 | 32.12 |
| $\mathcal{L}{CW} + \mathcal{L}{SE}$ | 42.23 | 38.01 | 33.45 | 40.45 | 36.23 | 32.78 |
| $\mathcal{L}{CW} + \mathcal{L}{SE} + \mathcal{L}_{DD}$ (Full) | 44.61 | 40.78 | 36.01 | 43.47 | 39.78 | 36.12 |
각 구성 요소의 효과
-
**Cluster-wise contrastive loss ($\mathcal{L}{CW}$)**: Instance-wise contrastive learning loss ($\mathcal{L}{IW}$)와 비교하여 더 나은 feature embedding을 학습합니다. Instance-wise 방법은 augmented views만을 positive로 고려하여 class semantic을 무시하지만, cluster-wise 방법은 semantic-aware features를 학습합니다.
-
Self-entropy loss ($\mathcal{L}_{SE}$): Clustering probabilities의 entropy 최소화가 cross-domain feature representation learning에 유익합니다. 이는 각 샘플이 하나의 cluster에 명확하게 할당되도록 하여 discriminative power를 향상시킵니다.
-
Distance-of-distance loss ($\mathcal{L}_{DD}$): Domain 간의 discrepancy를 최소화하여 최상의 alignment를 제공합니다. 특히 Real→Quickdraw와 같은 큰 domain gap이 있는 경우에 큰 성능 향상을 보입니다 (8.71% @ P@50).
4. Conclusion
본 논문은 도전적이지만 실용적으로 가치 있는 작업인 unsupervised cross-domain image retrieval을 위한 새로운 representation learning 프레임워크를 제시합니다. Category-level retrieval을 위한 class semantic-aware feature를 추출하기 위해, 유사한 semantic을 가진 샘플들을 가깝게 당기고 다른 clusters를 멀리 밀어내는 cluster-wise contrastive learning loss를 제안합니다. Cross-domain alignment를 위해, 도메인 간의 discrepancy를 효과적으로 측정하고 최소화하기 위한 novel distance-of-distance loss를 도입합니다.
Office-Home과 DomainNet 데이터셋에서의 실험 결과는 제안된 알고리즘의 우수성을 일관되게 보여줍니다.