Paper: CVPR 2024 paper
OpenAccess: CVF OpenAccess
Intro
이미지 검색(retrieval)은 query 이미지가 주어졌을 때 gallery 안에서 가장 비슷한 이미지를 찾는 문제다. 하지만 실제 환경에서는 단순히 “비슷하게 생긴 이미지”를 찾는 것만으로는 부족하다. 학습 시점에 보았던 도메인과 테스트 시점의 도메인이 다를 수 있고, 테스트에는 학습 중 한 번도 보지 못한 카테고리가 등장할 수도 있기 때문이다. 이런 더 어려운 설정을 다루는 문제가 Universal Cross-Domain Retrieval (UCDR) 이다.
UCDR은 두 가지 일반화를 동시에 요구한다.
- Domain generalization: 처음 보는 도메인에도 잘 동작해야 한다.
- Category generalization: 처음 보는 클래스에도 잘 동작해야 한다.
예를 들어 학습 단계에서는 real, sketch, quickdraw 도메인의 일부 클래스만 보았다고 하자. 테스트에서는 학습에 없던 도메인과 학습에 없던 클래스가 동시에 등장할 수 있다. 이때 모델은 도메인 차이에 흔들리지 않으면서도, 보지 못한 클래스까지 의미 공간으로 잘 매핑해야 한다.
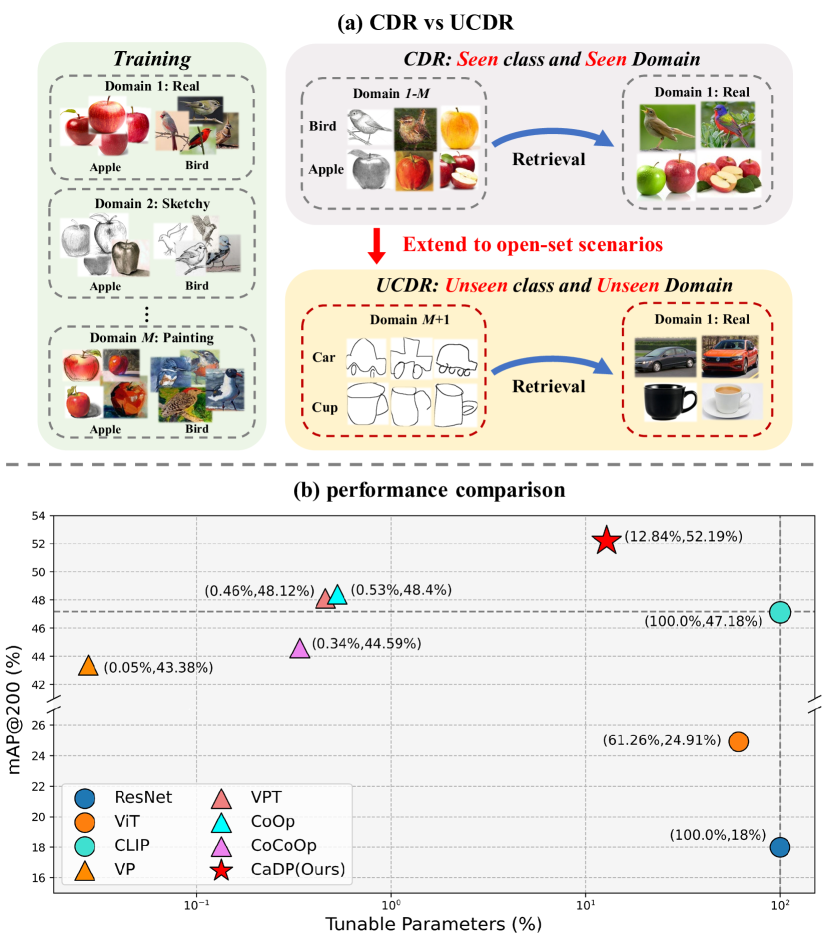
이 논문은 여기서 아주 자연스러운 질문을 던진다.
이미 CLIP 같은 대규모 사전학습 모델은 폭넓은 일반 지식을 가지고 있는데, 이 지식을 UCDR 문제에 더 잘 활용할 수 없을까?
CLIP은 zero-shot 인식과 분포 변화에 비교적 강한 모델이다. 하지만 저자들은 기존 prompt tuning을 그대로 적용하는 것만으로는 UCDR에 충분하지 않다고 지적한다. 계산 효율은 좋을 수 있지만 retrieval 성능에서는 full fine-tuning보다 큰 우세를 보이지 못한다. 이유는 기존 prompt tuning이 UCDR의 핵심인 도메인 변화와 카테고리 변화의 동시 일반화를 직접적으로 반영하지 못하기 때문이다.
이 문제를 해결하기 위해 논문은 Prompt-to-Simulate (ProS) 를 제안한다. 핵심은 CLIP에 고정 prompt를 단순 부착하는 대신, 학습 단계에서 테스트 상황을 미리 시뮬레이션하고 입력 내용에 따라 변하는 content-aware dynamic prompt를 생성하게 만드는 것이다.
Method
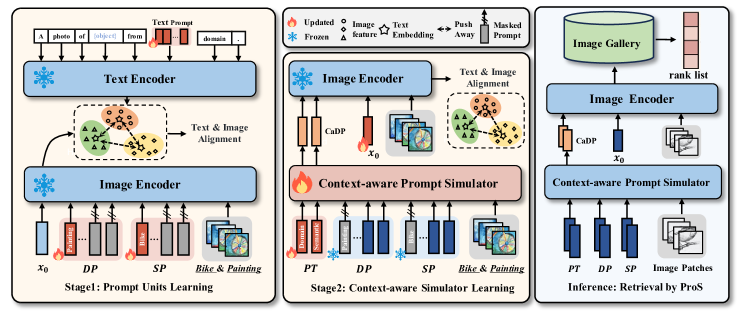
ProS는 크게 두 단계로 구성된다.
- Stage 1: Prompt Units Learning (PUL)
- Stage 2: Context-aware Simulator Learning (CSL)
PUL은 prompt unit 자체를 학습하는 단계이고, CSL은 그 unit들을 바탕으로 테스트 상황에 맞는 동적 prompt를 생성하는 단계다.
1. Preliminary: CLIP과 Prompt Tuning
CLIP은 이미지 인코더 (f(\cdot)) 와 텍스트 인코더 (g(\cdot)) 를 사용해 이미지와 텍스트를 같은 임베딩 공간에 정렬한다. 주어진 이미지 (x) 와 클래스별 텍스트 설명 (t_i) 들에 대해 CLIP 분류는 다음과 같이 쓸 수 있다.
\[\hat{y}_{clip}=\arg\max_i \left(f(x)\otimes g(t_i)\right)\]여기서 (\otimes) 는 cosine similarity다.
Prompt tuning은 CLIP 전체를 다시 학습하는 대신, 입력 쪽에 작은 학습 가능한 prompt만 추가해 적응시키는 방법이다. ProS는 이 prompt tuning의 효율성을 유지하면서도, UCDR에 필요한 일반화 방향으로 prompt를 더 구조적으로 설계한다.
2. Stage 1: Prompt Units Learning (PUL)
PUL의 목적은 간단하다. 도메인 정보와 의미 정보를 분리해 각각의 prompt가 자기 역할을 배우도록 만드는 것이다.
논문은 두 종류의 prompt unit을 둔다.
- Domain Prompt Units (DP): 각 source domain을 대표하는 prompt
- Semantic Prompt Units (SP): 각 seen class를 대표하는 prompt
수식으로 쓰면 다음과 같다.
\[DP=\{dp_i\in\mathbb{R}^{l}\}_{i=1}^{K}\] \[SP=\{sp_i\in\mathbb{R}^{l}\}_{i=1}^{|C_{train}|}\]| 여기서 (K) 는 source domain 수, ( | C_{train} | ) 은 학습에 사용되는 seen class 수다. |
PUL에서는 한 이미지가 들어올 때 모든 prompt를 동시에 쓰지 않는다. 대신 현재 이미지와 관련된 prompt만 선택적으로 활성화한다. 예를 들어 현재 입력이 Sketch 도메인의 dog 라면, domain prompt에서는 Sketch에 해당하는 prompt 하나만, semantic prompt에서는 dog에 해당하는 prompt 하나만 켠다.
즉 이 단계는 prompt를 일종의 역할 분담 사전처럼 만드는 과정이다.
- domain prompt는 domain-specific 정보만 학습하고
- semantic prompt는 class-specific 정보만 학습한다.
텍스트 쪽도 고정 템플릿 대신 learnable text prompt를 사용한다. 논문에서는 다음과 같은 텍스트 템플릿을 사용한다.
a photo of [CLASS] from Pt domain.
그리고 prompted image feature와 text feature를 alignment loss로 맞춘다.
\[\mathcal{L}=-\sum_{i=1}^{|C_{train}|} y_i \log \left(f(x^p)\otimes g(t_i)\right)\]저자들은 이 학습을 mask-and-align objective 라고 설명한다.
3. Stage 2: Context-aware Simulator Learning (CSL)
PUL만으로는 테스트 상황을 충분히 반영하지 못한다. PUL에서는 현재 이미지가 어느 도메인, 어느 클래스인지 알고 있고, 해당 prompt를 직접 활성화하기 때문이다. 하지만 실제 테스트에서는 정답 prompt를 사용할 수 없다. unseen domain과 unseen class가 동시에 등장할 수 있기 때문이다.
그래서 CSL의 목표는 다음과 같다.
테스트처럼 정답 정보를 직접 쓸 수 없는 상황에서도, 입력 이미지 내용에 맞는 prompt를 생성하도록 학습하자.
이를 위해 논문은 Content-aware Prompt Simulator (CaPS) 를 도입한다. CSL에서는 오히려 현재 샘플에 해당하는 정답 domain/class prompt를 일부러 가린다. 예를 들어 현재 이미지가 Sketch의 dog 라면, 그와 정확히 대응하는 domain prompt와 semantic prompt를 0으로 마스킹한다. 그리고 나머지 prompt unit들과 이미지 내용만 보고 새 prompt를 생성하도록 학습한다.
이 설계는 사실상 simulated test scenario 다. 학습 단계에서 일부 정보를 가려 실제 테스트처럼 더 어려운 상황을 만들고, 그 상태에서 모델이 적절한 prompt를 생성하도록 훈련한다.
- PUL은 “정답을 알려주고 배우는 단계”
- CSL은 “정답을 가린 상태에서 추론하도록 연습시키는 단계”
라고 이해하면 가장 직관적이다.
4. Retrieval by ProS
두 단계 학습이 끝나면 실제 retrieval 단계에서는 텍스트 인코더가 더 이상 필요하지 않다. 이미지 feature만 있으면 되기 때문이다.
Inference는 다음처럼 정리된다.
\[[P_d, P_s] = \mathcal{M}\left([P_T^d,\, P_T^s,\, DP,\, SP,\, E^0]\right)\] \[x = f([x^0,\, P_d,\, P_s,\, E^0])\] \[y = Head(x)\]즉 query와 gallery 모두 동일한 방식으로 feature를 추출한 뒤, similarity를 계산해 ranking을 수행한다.
Result
이 논문의 결과는 세 가지 관점에서 정리할 수 있다.
1. 기존 prompt tuning보다 더 강한 일반화
저자들은 기존 prompt tuning 방법들을 UCDR에 직접 적용했을 때 계산 효율은 좋지만 retrieval 성능 면에서는 full fine-tuning CLIP보다 뚜렷한 우세를 보이지 못했다고 설명한다. 반면 ProS는 UCDR의 구조를 반영해 설계되었기 때문에 unseen domain과 unseen category가 동시에 존재하는 환경에서도 더 좋은 성능을 낸다.
2. 정적인 prompt보다 동적인 prompt가 더 적합함
ProS의 핵심 메시지는 여기 있다. 기존 prompt tuning은 학습 후 고정 prompt를 사용하는 경우가 많다. 하지만 UCDR은 도메인과 카테고리의 변화가 동시에 존재하므로 하나의 고정 prompt로 모든 상황을 다루기 어렵다.
ProS는
- PUL에서 역할이 분리된 prompt unit을 배우고
- CSL에서 테스트처럼 정보를 숨긴 상황에서도 적절한 prompt를 생성하도록 학습함으로써
정적인 prompt가 아닌 content-aware dynamic prompt 를 사용한다.
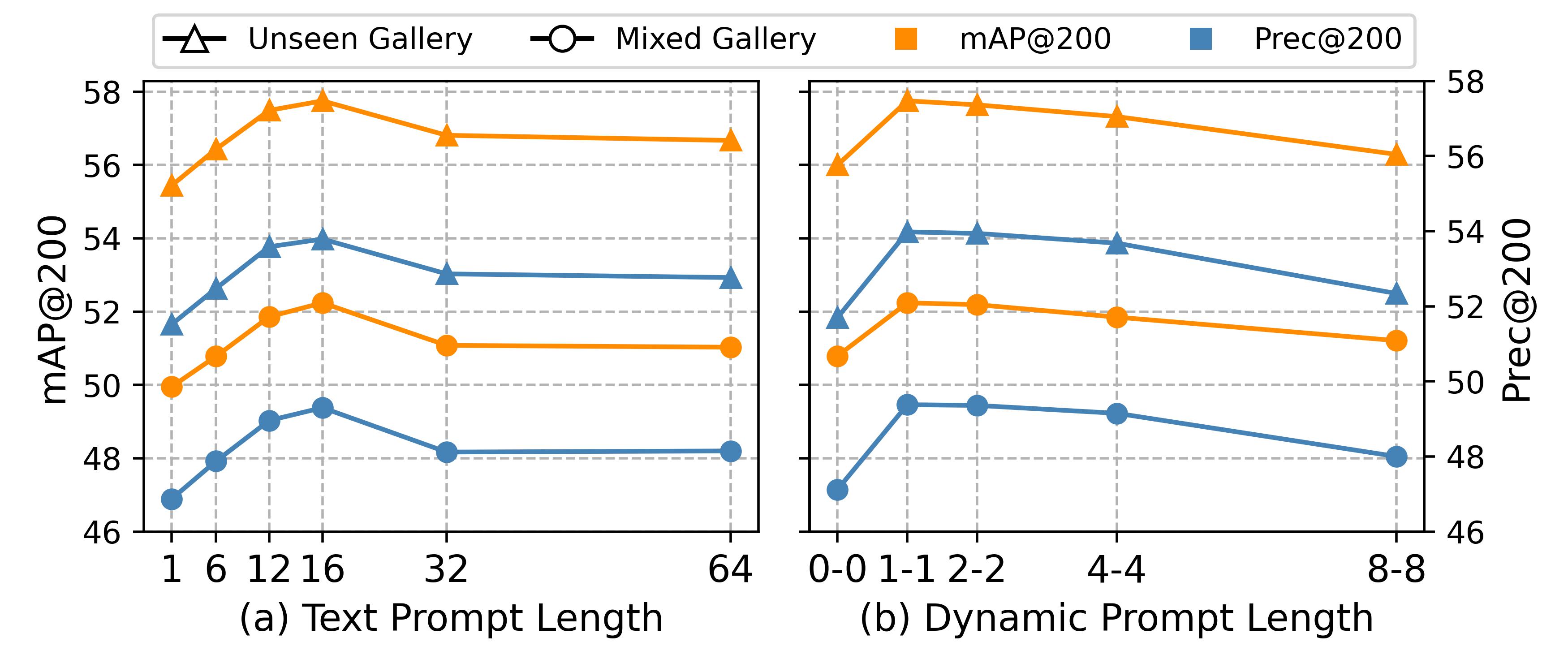
3. 큰 파라미터 증가 없이 성능 향상
논문은 제안한 방법이 강한 성능을 내면서도 과도한 파라미터 증가를 요구하지 않는다고 강조한다. 이는 foundation model인 CLIP 전체를 크게 수정하기보다, prompt design 자체를 더 똑똑하게 만든 결과라고 볼 수 있다.
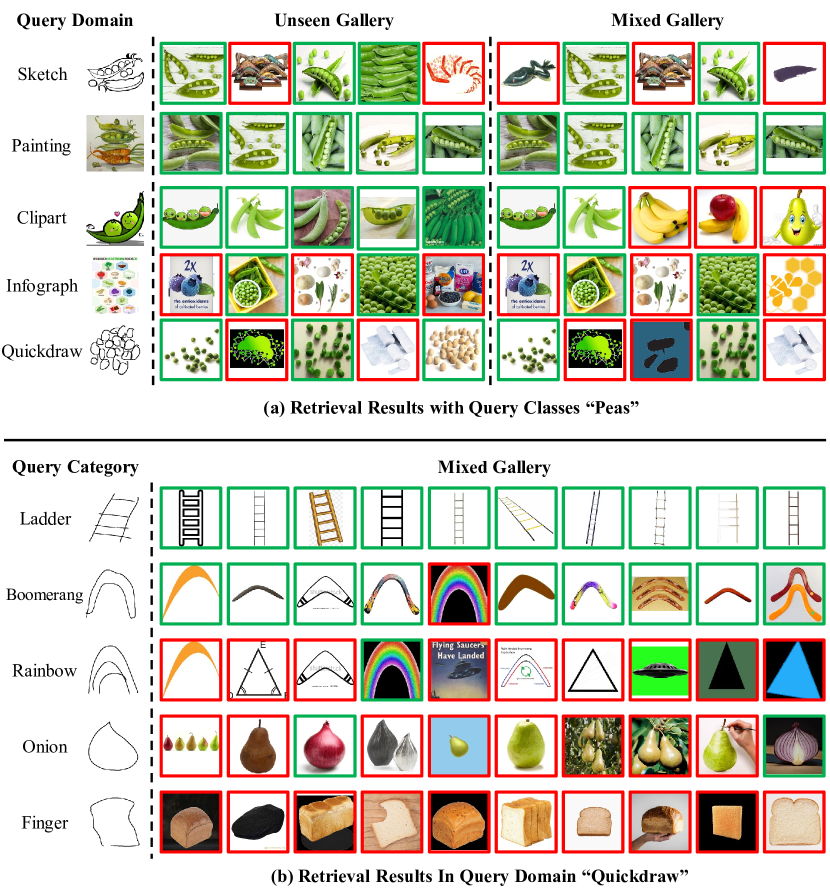
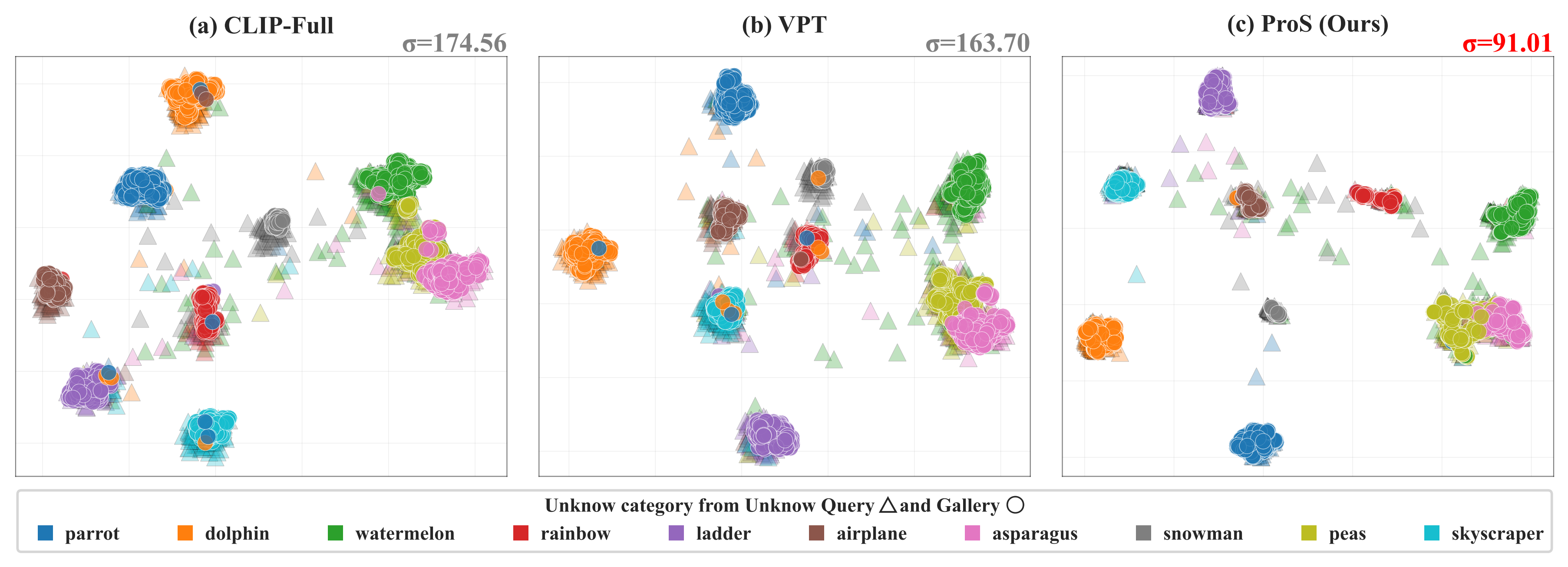
또한 feature visualization에서도 ProS가 unseen class들을 더 잘 분리하는 모습을 보인다. 이는 단순히 분류 점수만 높아진 것이 아니라, retrieval에 중요한 임베딩 구조 자체가 더 일반화되었다는 신호다.
정리
이 논문은 다음 질문에서 출발한다.
CLIP의 풍부한 일반 지식을, 테스트 정보가 거의 없는 UCDR 문제에서 더 잘 활용할 수 있을까?
그리고 그 답으로 Prompt-to-Simulate (ProS) 를 제안한다. ProS는 단순한 prompt learning이 아니라,
- PUL: 도메인 prompt와 의미 prompt를 분리해서 학습하고
- CSL: 테스트 상황을 시뮬레이션하며 동적 prompt를 생성하도록 학습한 뒤
- Inference: 이 동적 prompt를 CLIP image encoder에 넣어 더 일반화된 retrieval feature를 추출하는 방식
으로 구성된다.
결국 이 논문의 핵심은 다음 한 문장으로 요약할 수 있다.
ProS는 CLIP에 고정 prompt를 붙이는 대신, 도메인/의미 프롬프트를 분리해 학습하고 테스트 상황을 시뮬레이션함으로써 UCDR에 더 적합한 동적 prompt를 생성한다.