Paper: MaPLe: Multi-modal Prompt Learning
PDF: arXiv PDF
Code: GitHub
Abstract
이 파일은 원래 UCDR-Adapter 내용이 잘못 들어가 있었는데, 사용자가 준 논문 링크를 기준으로 확인해보면 실제 리뷰 대상은 MaPLe: Multi-modal Prompt Learning 이 맞다. 이 논문은 retrieval 논문이라기보다, CLIP을 few-shot 환경에서 더 잘 적응시키기 위한 prompt learning 논문이다.
핵심 문제의식은 단순하다. 기존 CLIP adaptation 방법인 CoOp, Co-CoOp은 대부분 텍스트 브랜치만 프롬프트를 학습한다. 하지만 CLIP은 애초에 vision encoder와 text encoder가 함께 정렬되는 구조이기 때문에, 한쪽만 조정하면 downstream task에 맞는 표현 정렬이 충분히 일어나지 않을 수 있다.
그래서 MaPLe는 다음 질문에서 출발한다.
CLIP을 적응시킬 때 text prompt만 만지는 것이 아니라, vision branch와 language branch를 함께 prompt tuning하면 더 잘 일반화할 수 있지 않을까?
논문은 이 질문에 대해 Multi-modal Prompt Learning (MaPLe) 을 제안한다. MaPLe는
- language branch에 deep prompts를 넣고
- vision branch에도 deep prompts를 넣되
- 둘을 완전히 독립적으로 두지 않고, language prompt로부터 vision prompt를 생성하는 coupling function 을 둔다.
이렇게 하면 두 모달리티가 따로 노는 것이 아니라 서로 연결된 상태로 학습된다.
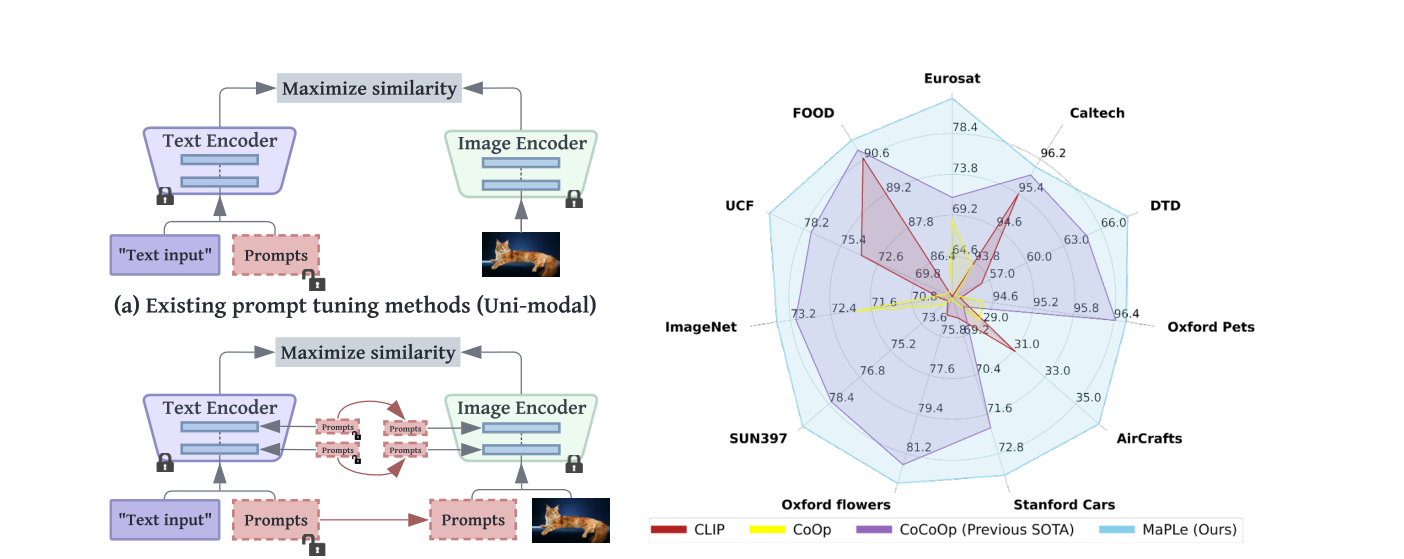
논문이 평가한 대표 시나리오는 세 가지다.
- Base-to-Novel Generalization: 학습한 base class에서 보지 못한 novel class로 얼마나 잘 일반화하는가
- Cross-dataset Transfer: ImageNet에서 학습한 뒤 다른 데이터셋으로 얼마나 잘 옮겨 가는가
- Domain Generalization: ImageNetV2, ImageNet-Sketch, ImageNet-A, ImageNet-R 같은 분포 변화에서 얼마나 robust한가
즉 MaPLe는 “few-shot prompt tuning이 정말 일반화에 도움이 되느냐”를 꽤 폭넓게 검증하는 논문이다.
Method
1. CLIP과 Prompt Learning의 기본 구조
CLIP은 image encoder와 text encoder가 같은 embedding space에서 만나도록 학습된 모델이다. 이미지 feature를 (x), 클래스별 text feature를 (z_i) 라고 하면, 분류 확률은 다음처럼 계산된다.
\[p(\hat{y}\mid x)= \frac{\exp(\mathrm{sim}(x,z_{\hat{y}})/\tau)} \sum_{i=1}^{C}\exp(\mathrm{sim}(x,z_i)/\tau)}\]여기서 (\mathrm{sim}(\cdot,\cdot)) 는 cosine similarity, (\tau) 는 temperature다.
기존 CoOp류 방법은 이때 text encoder 쪽 prompt만 학습한다. MaPLe는 여기서 한 발 더 나가서 vision과 language 양쪽 모두에 hierarchical prompt를 넣고, 둘 사이를 명시적으로 연결한다.
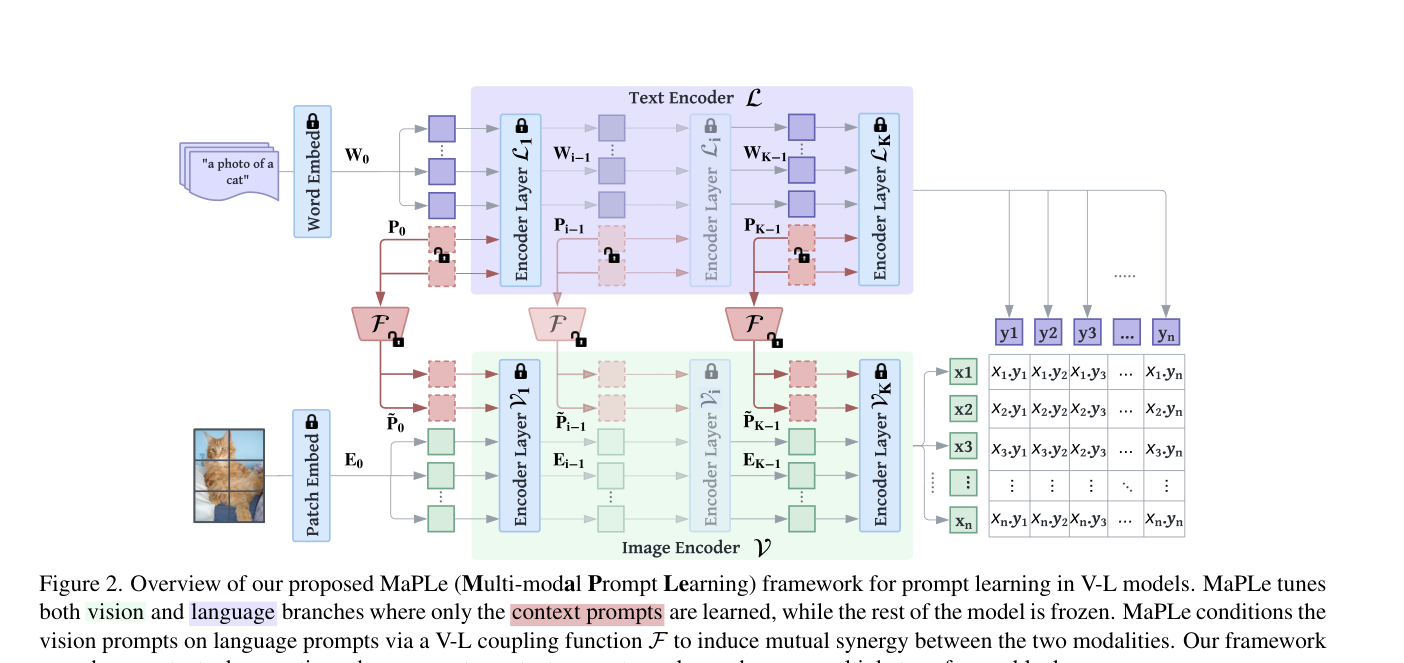
2. Deep Language Prompting
먼저 language branch에는 learnable prompt token (P) 를 넣는다. 이 prompt는 입력 한 번만 넣는 shallow prompting이 아니라, 초기 여러 transformer block에 걸쳐 단계적으로 삽입되는 deep prompting 구조다.
언어 브랜치에서 (J) 개 초기 레이어까지는 다음처럼 prompt와 token embedding을 함께 넣는다.
\[[P_i, W_i] = L_i([P_{i-1}, W_{i-1}]), \qquad i=1,\dots,J\]그 이후 레이어에서는 앞에서 갱신된 prompt를 계속 전달한다.
\[[P_j, W_j] = L_j([P_{j-1}, W_{j-1}]), \qquad j=J+1,\dots,K\]최종 텍스트 표현은 마지막 token을 projection해서 얻는다.
\[z = \mathrm{TextProj}(w_K^N)\]직관적으로 보면, shallow prompt가 “입구에서 한 번 힌트를 주는 방식”이라면, deep prompt는 여러 계층에서 문맥을 계속 보정하는 방식이다.
3. Deep Vision Prompting
MaPLe의 중요한 차별점은 image encoder에도 별도의 prompt를 넣는다는 점이다. vision branch에서도 learnable prompt (\tilde{P}) 를 초반 (J) 개 레이어에 주입한다.
\[[c_i, E_i, \tilde{P}_i] = V_i([c_{i-1}, E_{i-1}, \tilde{P}_{i-1}]), \qquad i=1,\dots,J\]그리고 최종 class token에서 image representation을 만든다.
\[x = \mathrm{ImageProj}(c_K)\]이 설계의 목적은 명확하다. text prompt만 바꾸는 것이 아니라 image feature space 자체도 downstream task에 맞게 조정하겠다는 것이다.
4. Vision-Language Prompt Coupling
하지만 양쪽 브랜치에 프롬프트를 넣는 것만으로는 충분하지 않다. text prompt와 vision prompt를 완전히 독립적으로 학습하면, 두 모달리티가 따로 최적화되어 shared alignment 가 약해질 수 있다.
그래서 MaPLe는 language prompt (P_k) 를 vision prompt (\tilde{P}_k) 로 사상하는 coupling function (F_k) 를 둔다.
\[\tilde{P}_k = F_k(P_k)\]그리고 vision branch는 이 coupled prompt를 사용한다.
\[[c_i, E_i, F_{i-1}(P_{i-1})] = V_i([c_{i-1}, E_{i-1}, F_{i-1}(P_{i-1})]), \qquad i=1,\dots,J\]논문에서 이 함수는 단순한 linear projection이지만, 역할은 중요하다.
- language prompt가 vision prompt의 출발점이 되므로
- 두 브랜치가 같은 task signal을 공유하게 되고
- gradient도 상호 연결되면서 uni-modal 해법으로 분리되는 것을 막는다.
즉 MaPLe의 본질은 “vision에도 prompt를 넣었다”보다, 두 브랜치의 prompt를 coupled하게 설계했다는 데 있다.
5. 왜 효과가 있는가
논문은 Co-CoOp와 MaPLe의 embedding을 t-SNE로 비교했을 때, MaPLe가 base class와 novel class를 더 잘 분리한다고 보여준다. 즉 vision prompt까지 함께 조정하면 CLIP의 image representation 자체가 더 task-aware해지고, 그 결과 novel class generalization도 좋아진다는 주장이다.
Result
MaPLe의 결과는 세 가지 관점에서 보면 된다.
1. Base-to-Novel Generalization
가장 중요한 결과는 11개 데이터셋 평균에서 나온다.
- CLIP: Base
69.34, Novel74.22, HM71.70 - CoOp: Base
82.69, Novel63.22, HM71.66 - Co-CoOp: Base
80.47, Novel71.69, HM75.83 - MaPLe: Base
82.28, Novel75.14, HM78.55
즉 MaPLe는 Co-CoOp 대비
- novel accuracy
+3.45 - harmonic mean
+2.72
의 평균 향상을 보인다.
특히 EuroSAT에서는 HM이 71.21 -> 82.35, FGVCAircraft에서는 27.74 -> 36.50, UCF101에서는 77.64 -> 80.77로 올라간다. 이건 domain shift가 크거나 generic하지 않은 시각 개념에서 MaPLe가 더 강하다는 논문 주장과도 맞는다.
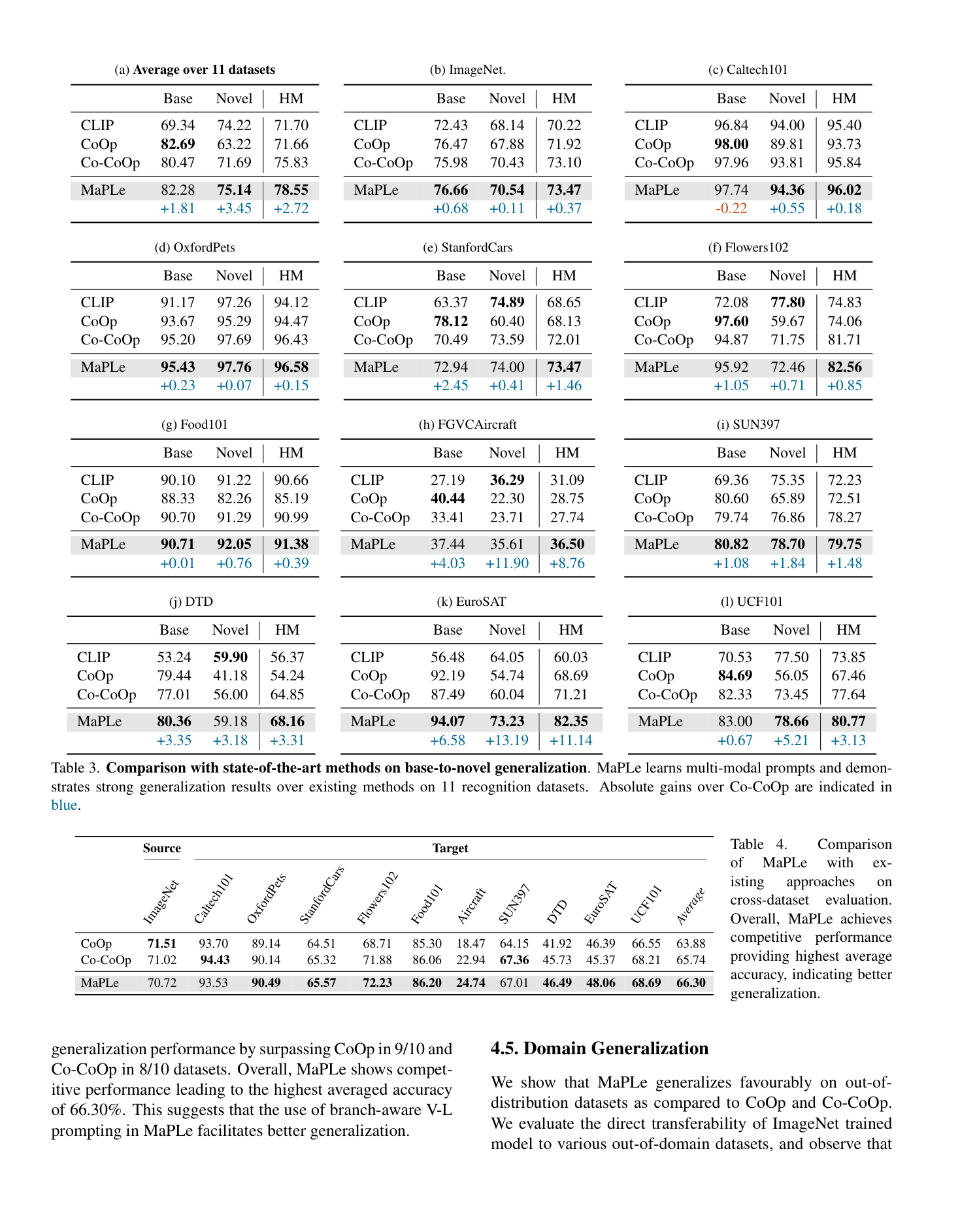
재미있는 포인트는 CoOp이 base class에 과적합하면서 novel class 성능이 크게 떨어지는 반면, MaPLe는 base 성능을 유지하면서 novel 성능까지 올린다는 점이다. 즉 “few-shot adaptation을 하되 zero-shot generalization을 덜 망가뜨린다”가 강점이다.
2. Prompt Design Ablation
논문은 왜 coupling이 중요한지도 ablation으로 보여준다.
- Deep vision prompting only: HM
76.68 - Deep language prompting only: HM
77.56 - Independent V-L prompting: HM
77.90 - MaPLe: HM
78.55
즉 vision과 language를 둘 다 쓰는 것만으로도 좋아지지만, 둘을 독립적으로 두는 것보다 coupled하게 묶었을 때 가장 성능이 좋다.
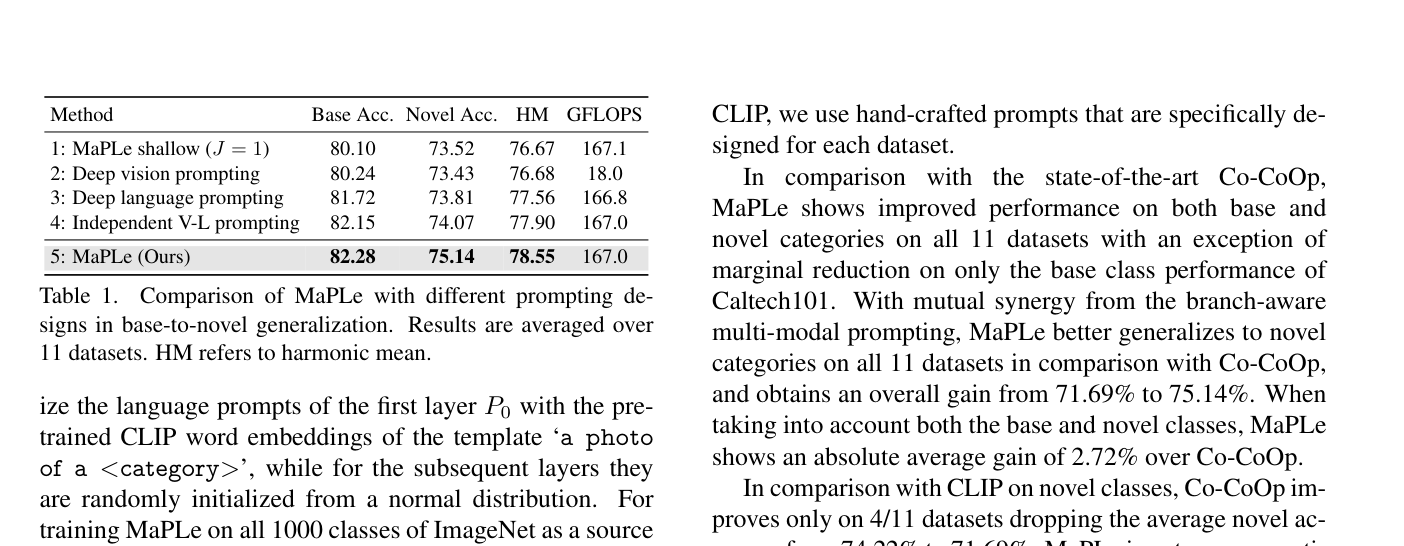
이 결과는 MaPLe의 핵심 메시지를 잘 보여준다. 단순히 prompt를 더 많이 넣은 것이 아니라, 모달리티 간 상호작용을 설계한 것이 중요하다는 것이다.
3. Cross-dataset Transfer와 Domain Generalization
ImageNet에서 학습하고 다른 데이터셋으로 옮기는 cross-dataset setting에서도 MaPLe는 평균 66.30으로 Co-CoOp의 65.74보다 높다. 큰 폭은 아니지만 평균적으로 가장 안정적이다.
도메인 일반화에서도 MaPLe는 일관된 개선을 보인다.
- ImageNet-Sketch:
48.75 -> 49.15 - ImageNet-A:
50.63 -> 50.90 - ImageNet-R:
76.18 -> 76.98
즉 완전히 새로운 데이터셋이든, 같은 ImageNet 계열의 distribution shift든, multi-modal prompting이 robust한 transfer를 만들어준다는 해석이 가능하다.
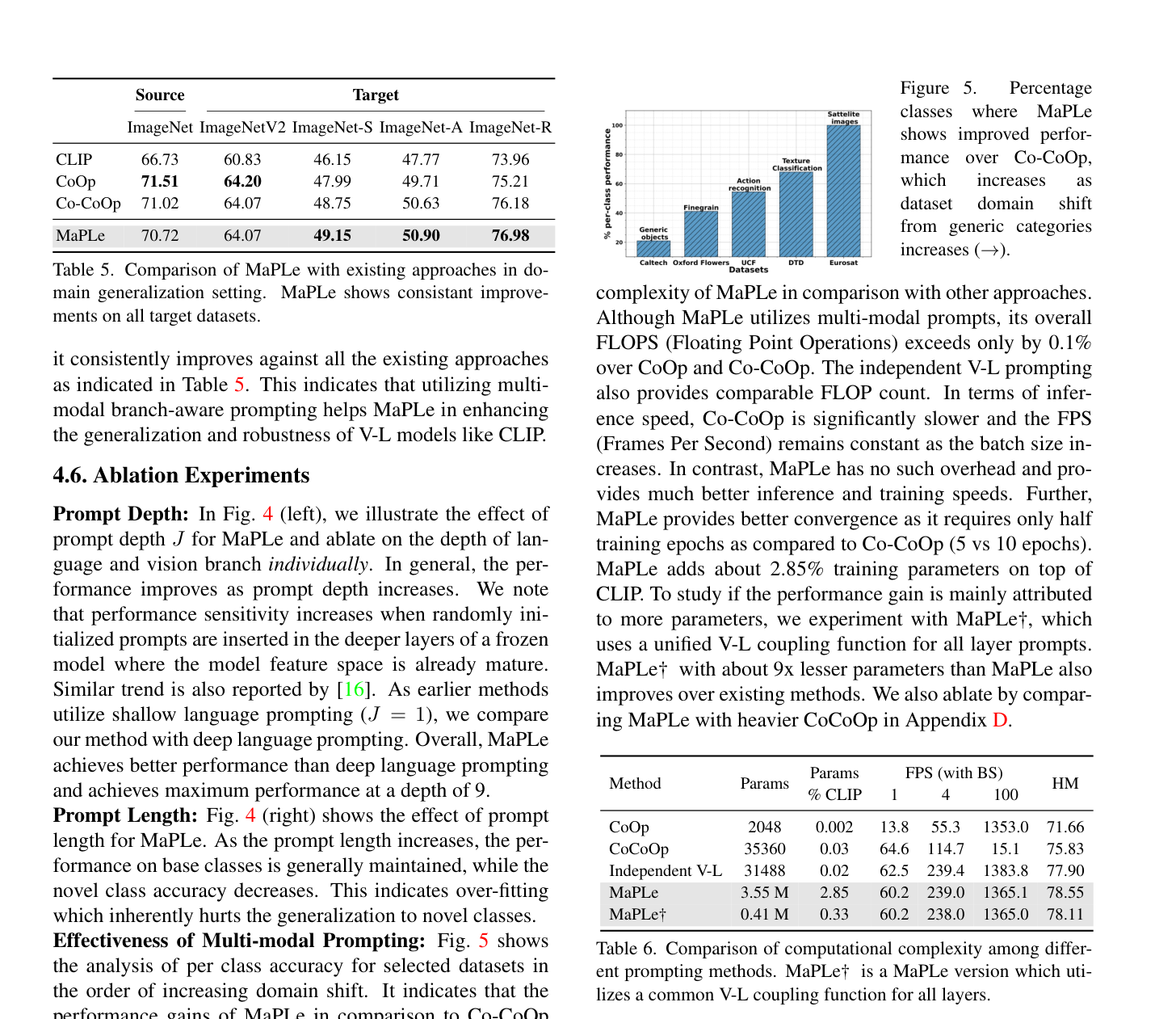
4. Prompt Depth와 Length
추가 ablation에서는 prompt depth가 깊어질수록 성능이 좋아지는 경향이 있고, 반대로 prompt length를 너무 길게 하면 novel accuracy가 떨어진다. 논문은 이를 overfitting 신호로 해석한다. 즉 “prompt를 깊게 넣는 것”과 “prompt를 길게 늘리는 것”은 다르게 작동한다.
정리
MaPLe는 CLIP adaptation에서 중요한 질문을 던진다.
prompt tuning을 한다면, 왜 text encoder만 만져야 하는가?
그리고 답은 꽤 설득력 있다.
- language branch만 prompt tuning하면 adaptation이 반쪽짜리일 수 있고
- vision branch까지 함께 조정하되
- 두 모달리티 prompt를 coupling function으로 연결하면
- base class에 과적합하지 않으면서 novel class generalization을 더 잘 유지할 수 있다.
한 문장으로 요약하면 이렇다.
MaPLe는 CLIP의 vision과 language 양쪽에 deep prompts를 넣고, language prompt로 vision prompt를 조건부 생성해 두 브랜치를 함께 적응시키는 multi-modal prompt learning 방법이다.
개인적으로 이 논문이 중요한 이유는, 이후 prompt tuning 계열 연구들이 왜 “uni-modal prompting만으로는 부족한가”를 설명하는 기준점이 되기 때문이다. CoOp, Co-CoOp 이후의 흐름에서 보면 MaPLe는 단순 성능 개선 논문이 아니라, prompt tuning의 대상과 결합 방식 자체를 확장한 논문으로 읽는 편이 더 정확하다.