Paper: WACV 2025 paper
PDF: OpenAccess PDF
Intro
Universal Cross-Domain Retrieval(UCDR)은 단순히 “다른 도메인에서도 retrieval이 잘 되는가”만 보는 문제가 아니다. 테스트 시점에는 보지 못한 도메인과 보지 못한 클래스가 동시에 등장할 수 있고, 모델은 semantic label 없이도 query와 같은 의미의 이미지를 gallery에서 찾아야 한다. 그래서 이 문제는 사실상 두 일반화를 동시에 요구한다.
- Domain generalization: unseen domain에서도 feature가 흔들리지 않아야 한다.
- Category generalization: unseen class도 의미적으로 구분할 수 있어야 한다.
논문은 이 설정을 세 가지 하위 시나리오로 정리한다.
- UCDR: unseen domain + unseen class
- UdCDR: unseen domain + seen class
- UcCDR: seen domain + unseen class
기존 CLIP 기반 방법들은 prompt tuning으로 이 문제를 풀려고 했지만, 저자들은 여기서 두 가지 한계를 본다.
- 고정된 static prompt는 새로운 분포 변화에 민감하게 적응하기 어렵다.
- unseen domain / unseen class를 동시에 다루려면, 단순 prompt 삽입보다 더 구조적인 adaptation이 필요하다.
그래서 이 논문은 UCDR-Adapter 를 제안한다. 핵심은 pre-trained CLIP을 그대로 크게 뜯지 않으면서도,
- source domain에서 class/domain prompt를 학습하고
- 테스트처럼 정답 class/domain을 가린 상태에서 target prompt를 생성하며
- 최종적으로 text branch 없이 image branch만으로 retrieval을 수행
하도록 만드는 것이다.
즉 이 논문의 질문은 다음과 같이 요약할 수 있다.
CLIP의 일반 지식을 유지하면서도, unseen domain과 unseen class에 더 잘 적응하도록 만들 수 있을까?
Method
UCDR-Adapter는 두 단계로 구성된다.
- Phase 1: Source Adapter Learning
- Phase 2: Target Prompt Generation
전반적인 구조는 아래 그림이 가장 잘 보여준다.
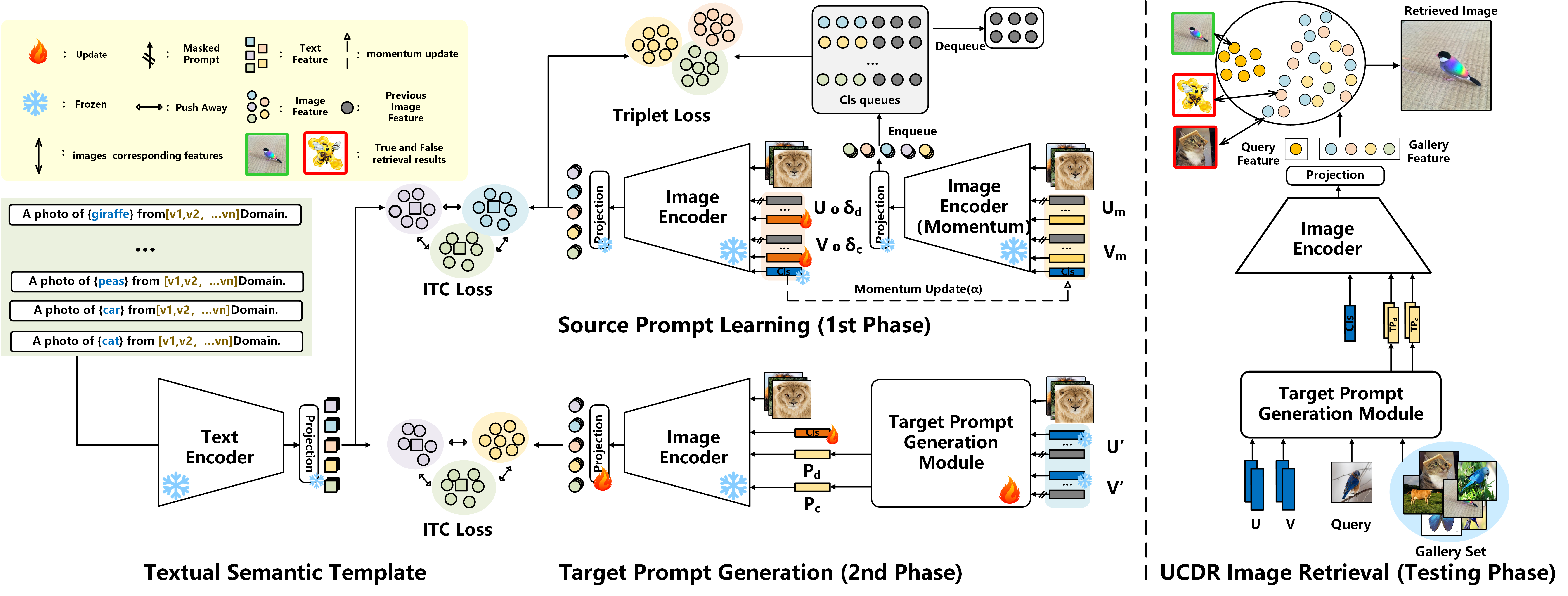
1. Source Adapter Learning
첫 단계의 목표는 source domain에서 class semantics 와 domain-specific visual knowledge 를 함께 정리하는 것이다. 이를 위해 논문은 text branch와 image branch 양쪽에 학습 가능한 요소를 둔다.
- Learnable Textual Semantic Template
-
Domain Prompts (U \in \mathbb{R}^{ D_{tr} \times m}) -
Class Prompts (V \in \mathbb{R}^{ C_{tr} \times m})
이미지 (IMG_i^{c,d}) 가 class (c), domain (d) 에 속하면, 해당 class/domain row만 마스크로 선택해 prompt를 만든다.
\[p = [V \circ \delta_c;\, U \circ \delta_d]\]여기서 (\delta_c, \delta_d) 는 현재 샘플의 class/domain row를 선택하는 mask다. 이 prompt는 vision encoder 입력에 더해지고, 텍스트 쪽에서는 semantic template와 domain-aware textual vector를 통해 class 의미와 domain 힌트를 함께 반영한다.
이 단계에서 중요한 건 prompt를 단순 lookup table로 두지 않고 momentum queue 기반으로 더 안정적으로 업데이트한다는 점이다. 논문은 MoCo 스타일의 momentum update를 사용한다.
\[\theta_M^{(t+1)} = (1-\alpha)\theta_M^{(t)} + \alpha \theta_C^{(t)}\]여기서 (\theta_M) 은 momentum prompt, (\theta_C) 는 현재 prompt 파라미터다. 이렇게 하면 batch 크기에 덜 묶이면서 class별 feature 다양성을 더 넓게 모을 수 있다.
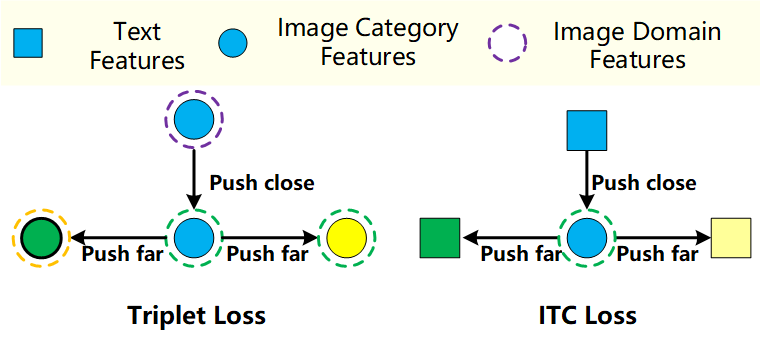
또한 학습은 단순 image-text contrastive loss만 쓰지 않고, class queue를 이용한 triplet loss를 같이 사용한다.
\[\mathcal{L}_{triplet} = \frac{1}{r}\sum_{i=1}^{r} \max\left(0, \|I_f^c-I_p\|^2 - \|I_f^c-I_n\|^2 + b \right)\]직관적으로 보면:
- ITC loss는 image-text semantic alignment를 맞추고
- triplet loss는 class 간 retrieval margin을 강하게 만든다.
2. Target Prompt Generation
첫 단계만으로는 아직 source domain/class에 의존적이다. 실제 테스트에서는 현재 이미지가 어느 class인지, 어느 domain인지 알 수 없기 때문이다. 그래서 두 번째 단계에서는 아예 정답 prompt를 가린 상태에서 target prompt를 생성한다.
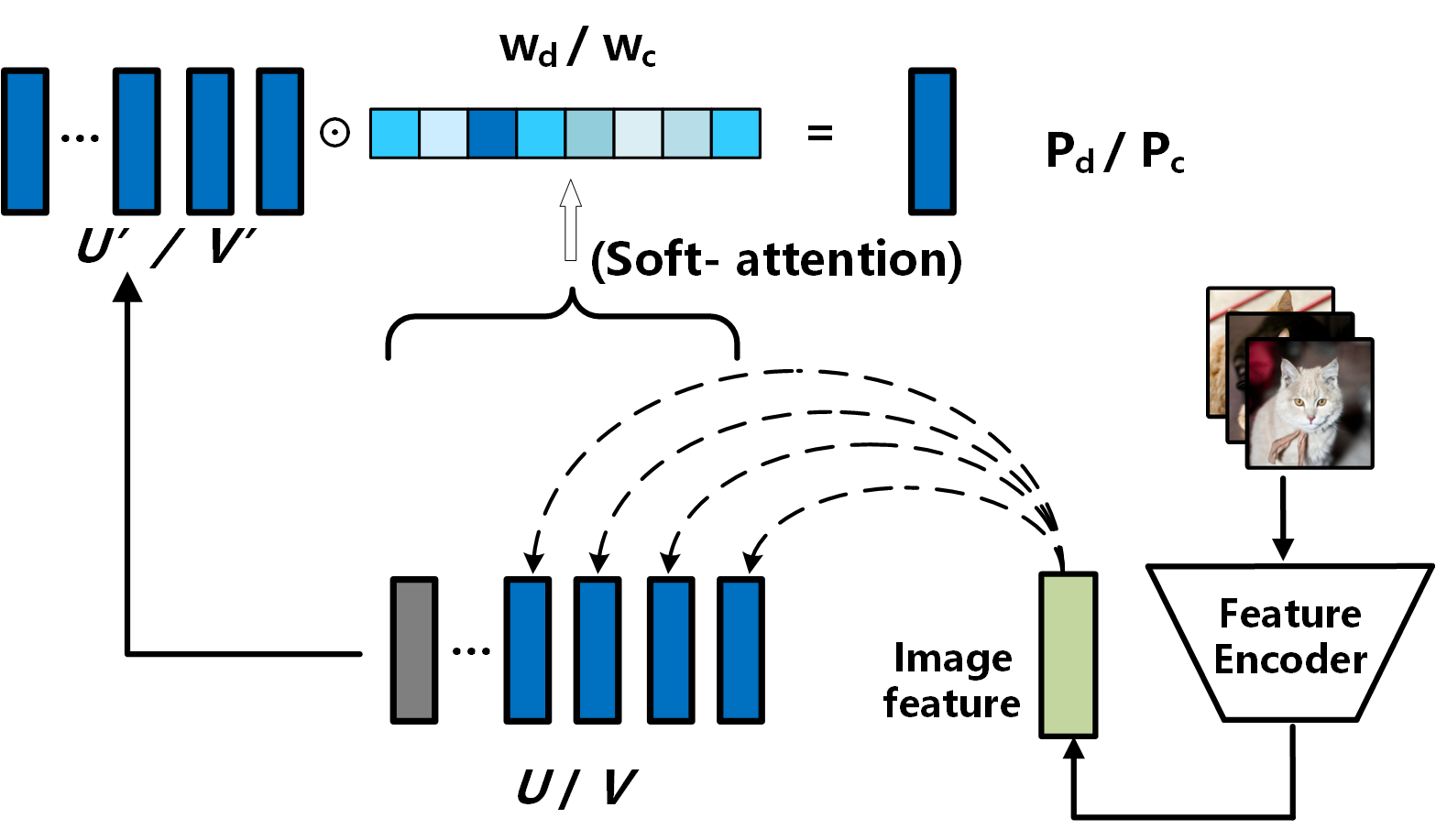
먼저 현재 이미지의 class/domain에 해당하는 row를 마스킹한다.
\[U' = U \circ (1-\delta_d), \qquad V' = V \circ (1-\delta_c)\]그리고 이미지 feature (I_g) 를 기반으로, 남아 있는 prompt들 위에 soft attention을 계산한다.
\[w_d = \mathrm{Attn}(I_g, U'), \qquad w_c = \mathrm{Attn}(I_g, V')\]이 attention weight를 이용해 unseen 상황에 맞는 target prompt를 동적으로 합성한다.
\[P_d = U' w_d, \qquad P_c = V' w_c\]핵심은 이 부분이다. ProS가 dynamic prompt를 강조했다면, UCDR-Adapter는 source에서 학습한 prompt bank 위에 attention 기반 adaptation을 얹고, adapter-style tuning으로 CLIP을 더 task-specific하게 맞춘다는 점이 다르다.
즉 이 단계는 “모르는 class/domain이라도 source prompt 조합을 바탕으로 가장 그럴듯한 target prompt를 생성한다”는 아이디어다.
3. Testing Phase
테스트 시점에서는 text semantic 정보가 없다고 가정한다. 따라서 text branch는 버리고, image branch만 사용한다. query와 gallery 모두 TPG를 통해 adapted prompt를 만든 뒤, image encoder feature를 추출하고 Euclidean distance로 retrieval ranking을 수행한다.
이 설계가 중요한 이유는 명확하다.
- 학습 때는 text supervision을 활용해 semantic anchor를 만들고
- 테스트 때는 image branch만 남겨도 retrieval이 가능하도록 구조를 짠 것
즉 “학습은 multimodal, 추론은 unimodal” 구조다.
Result
결과는 비교적 분명하다. UCDR-Adapter는 DomainNet, Sketchy, TU-Berlin 전반에서 기존 CLIP 기반 방법들보다 강하거나 비슷한 성능을 보이며, 특히 Zero-shot CLIP 대비 큰 폭의 향상을 보여준다.
1. DomainNet UCDR 성능
가장 대표적인 DomainNet UCDR setting에서 평균 성능은 다음과 같다.
- Zero-Shot CLIP:
mAP@200 0.4435,Prec@200 0.3840 - ProS:
mAP@200 0.6052,Prec@200 0.5626 - UCDR-Adapter:
mAP@200 0.6071,Prec@200 0.5655
Seen+Unseen gallery 설정에서도:
- ProS:
mAP@200 0.5546,Prec@200 0.5195 - UCDR-Adapter:
mAP@200 0.5660,Prec@200 0.5311
즉 평균적으로는 ProS보다 소폭 더 높고, zero-shot CLIP과의 차이는 훨씬 크다.
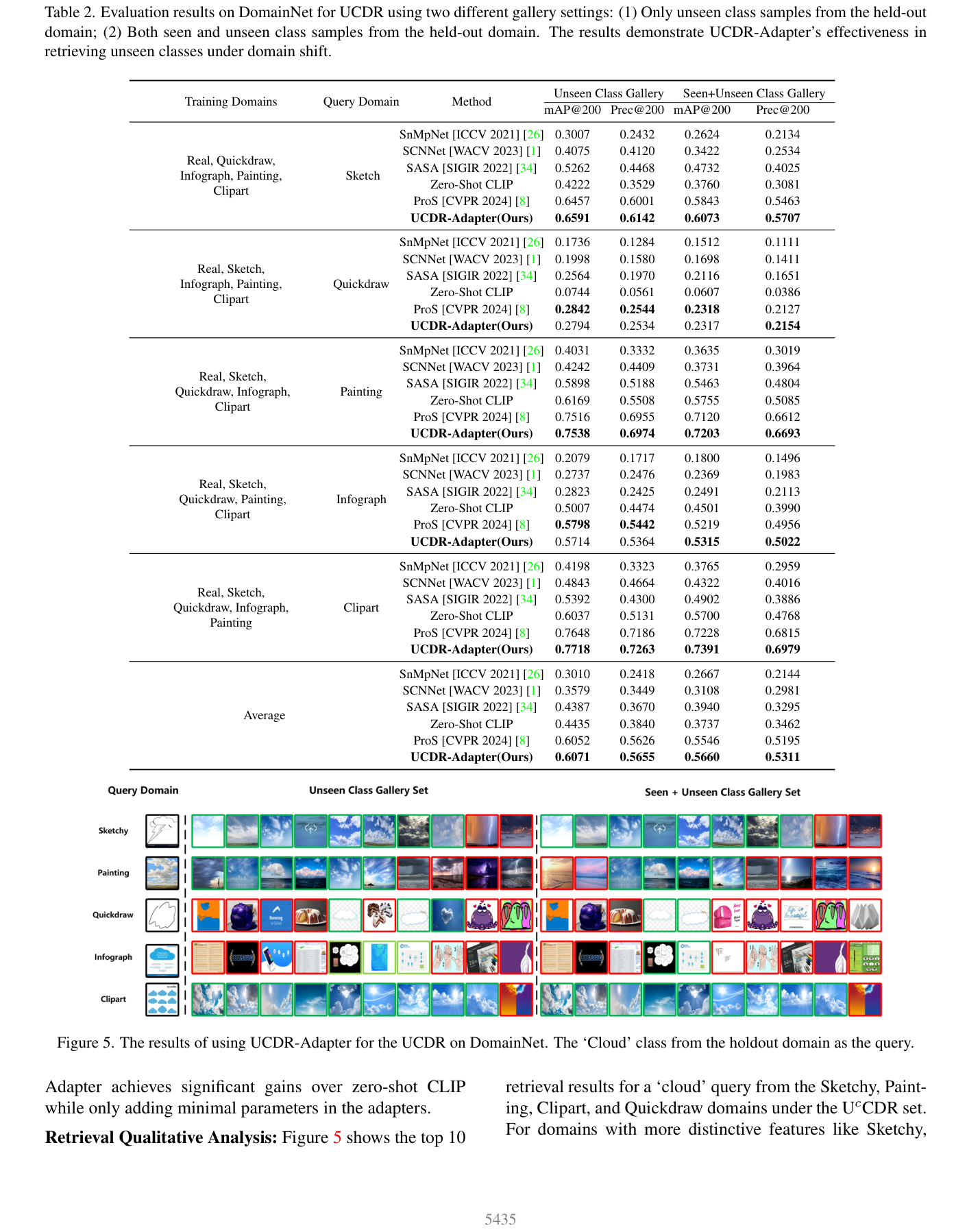
흥미로운 점은 모든 holdout domain에서 항상 큰 격차로 이기는 것은 아니라는 것이다. 예를 들어 Quickdraw처럼 정보가 거친 도메인에서는 ProS와 거의 비슷하거나 일부 metric에서 약간 낮다. 대신 평균적으로는 더 안정적이고, mixed gallery에서 이득이 더 또렷하다.
2. UdCDR / UcCDR 일반화
추가 실험에서도 메시지는 일관적이다.
- UdCDR 평균
- ProS:
mAP@200 0.6332 - UCDR-Adapter:
mAP@200 0.6370
- ProS:
- UcCDR on Sketchy
- ProS:
mAP@200 0.6991 - UCDR-Adapter:
mAP@200 0.7285
- ProS:
- UcCDR on TU-Berlin
- ProS:
mAP@all 0.6675 - UCDR-Adapter:
mAP@all 0.6581
- ProS:
즉 UCDR-Adapter는 domain generalization에서는 평균 우세를 보이고, class generalization에서는 Sketchy에서 강하지만 TU-Berlin에서는 ProS보다 약간 낮다. 논문이 주장하는 포인트는 “모든 setting에서 압도적 SOTA”라기보다, adapter + dynamic prompt 구조가 전반적으로 robust한 generalization을 만든다에 가깝다.
3. Ablation이 말해주는 것
ablation 결과는 구조적 메시지가 더 중요하다.
- 단순 fine-tuning CLIP은 오히려 성능이 낮다.
- linear probing보다 prompt tuning을 같이 쓰는 편이 낫다.
- two-phase 구조로 바꾸면 성능이 크게 오른다.
- masking, textual semantic template, triplet pair 증가가 모두 추가 이득을 준다.
특히 Sketchy holdout setting 기준으로:
U + V + TPG:mAP@200 0.6187+ Mask:0.6253+ TST:0.6540+ LTriple(pair 1):0.6560Full:0.6591
즉 이 방법의 성능은 한 가지 트릭보다, prompt bank + masking + target prompt generation + metric learning 이 함께 작동하면서 나온 결과다.

정리
UCDR-Adapter는 CLIP adaptation을 단순히 “prompt를 넣는다” 수준에서 끝내지 않는다. 이 논문은 UCDR을 다음처럼 쪼개서 다룬다.
- source domain에서 class/domain prompt를 분리 학습하고
- momentum queue와 triplet loss로 retrieval-friendly embedding을 만들고
- 테스트처럼 정답 정보를 가린 상태에서 target prompt를 생성해 unseen 상황을 시뮬레이션한다.
결국 핵심은 다음 한 문장으로 요약할 수 있다.
UCDR-Adapter는 source prompt bank를 학습한 뒤, attention 기반 target prompt generation으로 unseen class/domain에 적응하며, adapter-style CLIP tuning을 통해 UCDR 일반화를 끌어올린다.
개인적으로 이 논문의 장점은 ProS의 “dynamic prompt” 아이디어를 더 실용적인 adaptation 관점으로 확장했다는 데 있다. 특히 text supervision을 학습 시점에만 쓰고, 추론에서는 image branch만 남기는 설계가 retrieval 시스템 관점에서 꽤 깔끔하다. 반면 성능이 모든 benchmark에서 압도적으로 벌어지는 것은 아니라서, 이후 논문들은 DePro처럼 prompt decoupling이나 domain ensemble 쪽으로 더 나아가게 된다. 그런 의미에서 UCDR-Adapter는 ProS와 DePro 사이를 잇는 중간 단계의 설계로 읽으면 가장 이해하기 쉽다.