
Experience
 AX Technology R&D Group · Spatial Intelligence Vision Engineer · POSCO DX
AX Technology R&D Group · Spatial Intelligence Vision Engineer · POSCO DX
Pangyo, Korea · July 2024 - Present
- Isaac Sim·PLC·Sim2Real: Built physical-AI training environments that mirrored steel-site conditions and iterated models against real deployment constraints.
- Dataiku·SDD·MLOps: Advanced Digital Transformation (DX) from smart factory to intelligence factory by building SDD-driven image retrieval and automated MLOps pipelines for steel vision systems.
- Autonomous Steelmaking·L2 Integration·Vision AI: Integrated L2 communications and control signals to apply vision-based anomaly detection in autonomous steelmaking operations.
 AI Research Engineer · VUNO Inc.
AI Research Engineer · VUNO Inc.
Seoul, Korea · May 2021 - July 2024
- Test-Time Adaptation·Domain Adaptation·ACCV 2024: Developed adaptation strategies for medical imaging domain shifts and contributed to the CNG-SFDA research line published at ACCV 2024.
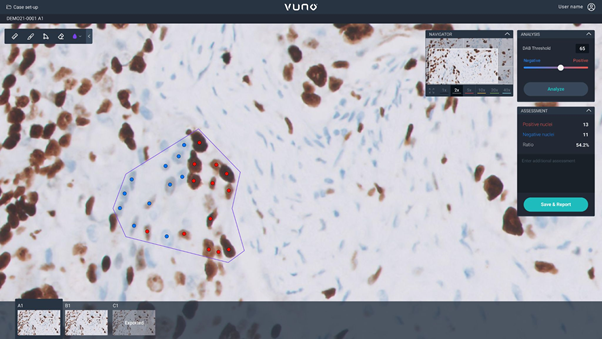
- Self-Supervised Learning·Universal Segmentation·TIGER Challenge: Conducted segmentation-oriented SSL research, built pathology workflows around it, and applied the stack to achieve 1st place in the TIGER Challenge.
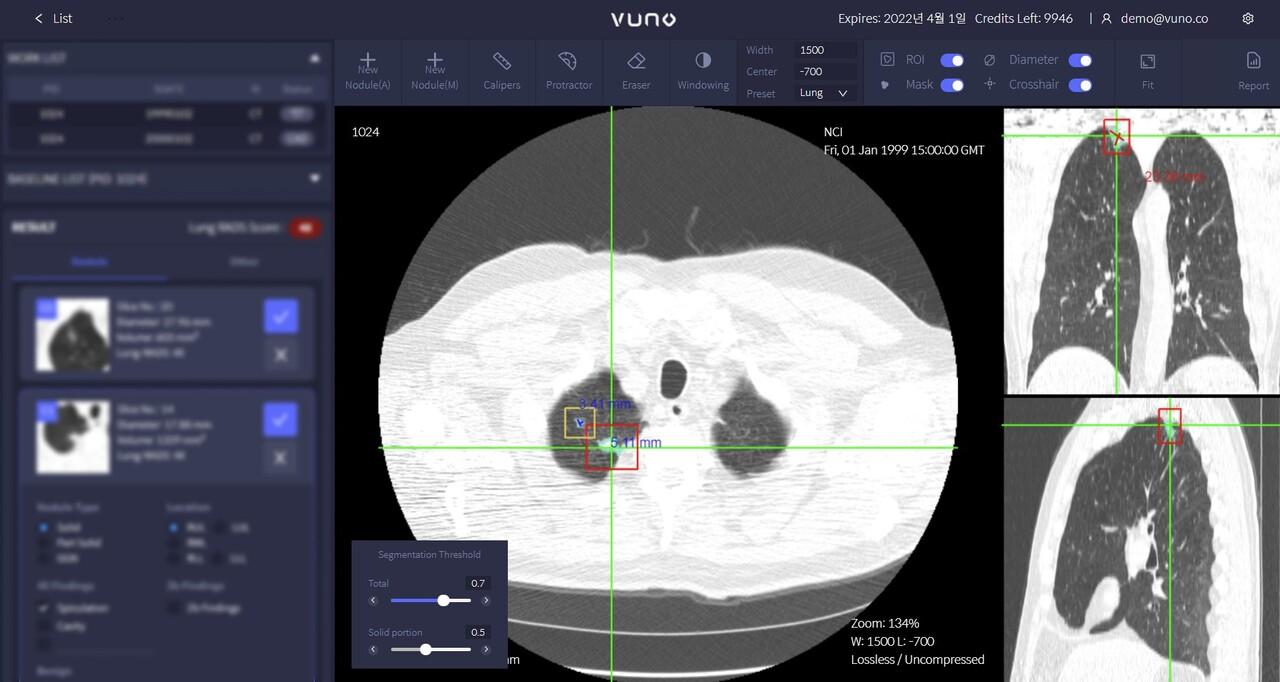
- Lung CT·3D Tiny Object Detection·MLOps: Built and deployed lung nodule detection pipelines for 3D tiny-object modeling, with production-grade monitoring and release workflows in real service environments.
- PathQuant·End-to-End Delivery·Applied Engineering: Owned the full cycle from data collection and model refinement to packaging and final deployment, demonstrating strong applied-engineer execution in medical imaging products.
Education
 M.S. in Computer Science · UNIST
M.S. in Computer Science · UNIST
Ulsan, Korea · Mar 2019 - Mar 2021
Cumulative GPA 3.28/4.3, Scholarships: Academic excellence for 4 semesters (2019-2021)
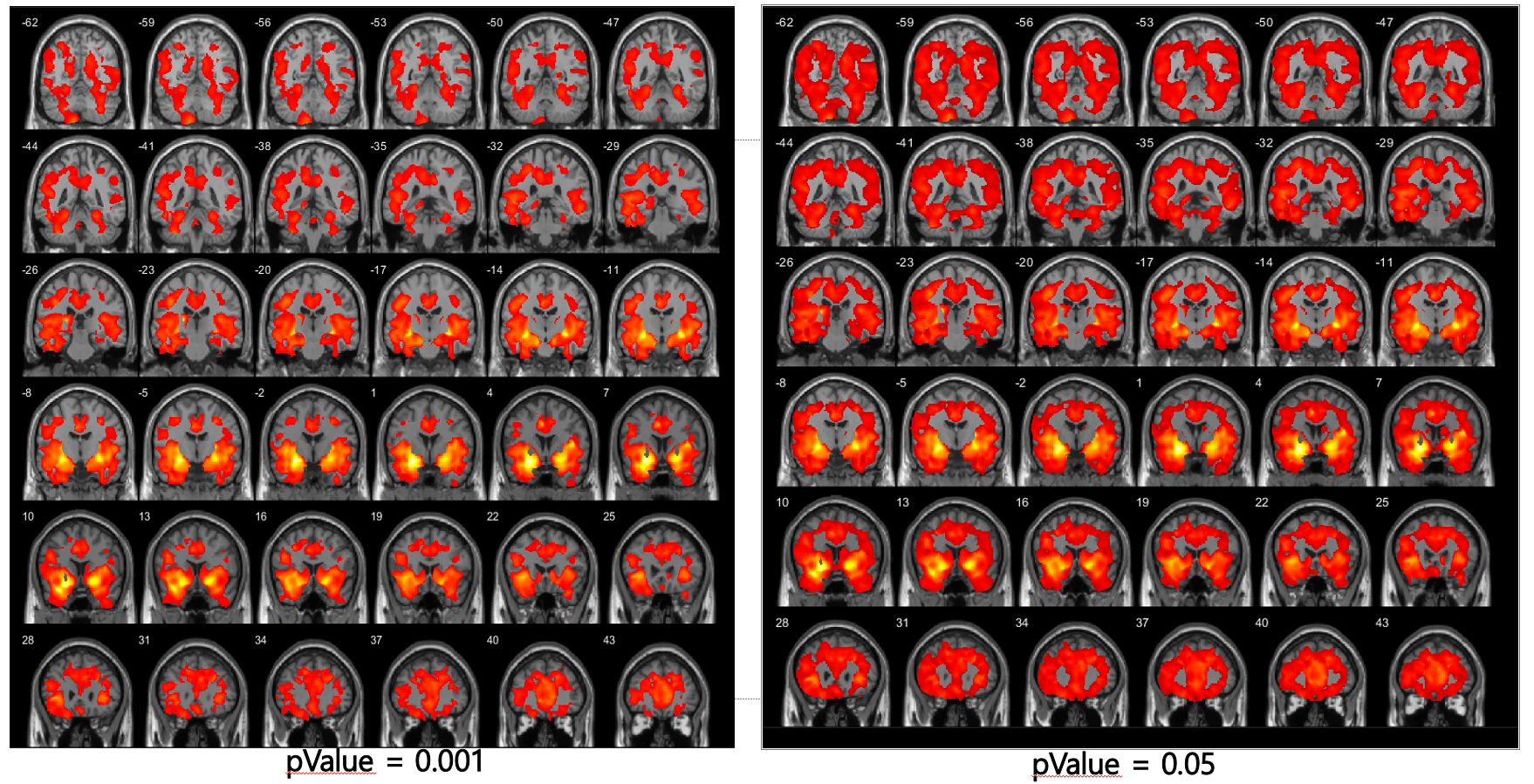
Thesis: Neuron segmentation using incomplete and noisy labels via adaptive learning with structure priors
Domestic Patent: Brain Neural Network Structure Image Processing System, Brain Neural Network Structure Image Processing Method, and a computer-readable storage medium
 B.S. in Biomedical Engineering · Inje University
B.S. in Biomedical Engineering · Inje University
Gimhae, Korea · Mar 2014 - Aug 2018
Cumulative GPA 3.89/4.5, Scholarships: Academic excellence for 8 semesters (2014-2018)
Awards: Gold Prize: Inje Creative Comprehensive Design Contest; Bronze Prize: 2017 Engineering Festival Competition; Good Capstone Design Contest
Projects

Seminar & Teaching
딥러닝을 활용한 의료 영상 처리 & 모델 개발
Seoul, Korea · Sep 2023 - Dec 2023

의용공학과에서 AI연구원되기까지
Gimhae, Korea · 2023 - 2024
Provided guidance and mentorship to students in computer vision and machine learning projects.

Image Classification · Machine Learning Course
Seongnam, Korea · 2023 - 2024
Taught machine learning fundamentals and applications to university students.
Publications & Research
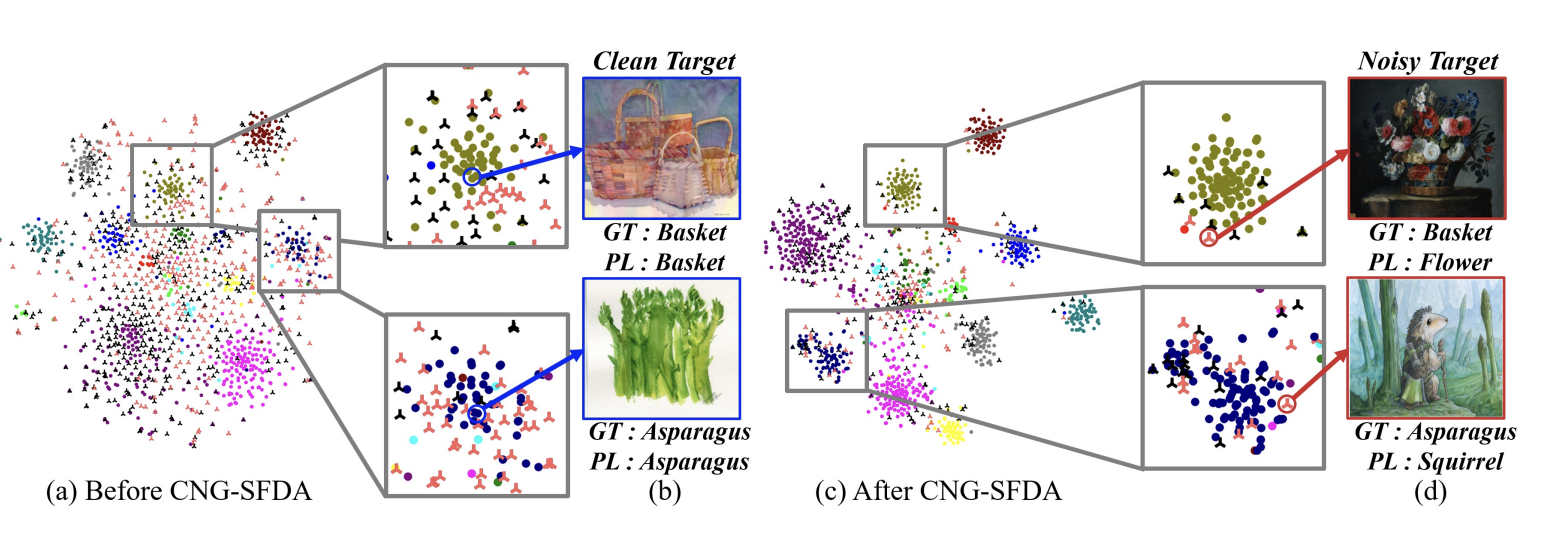
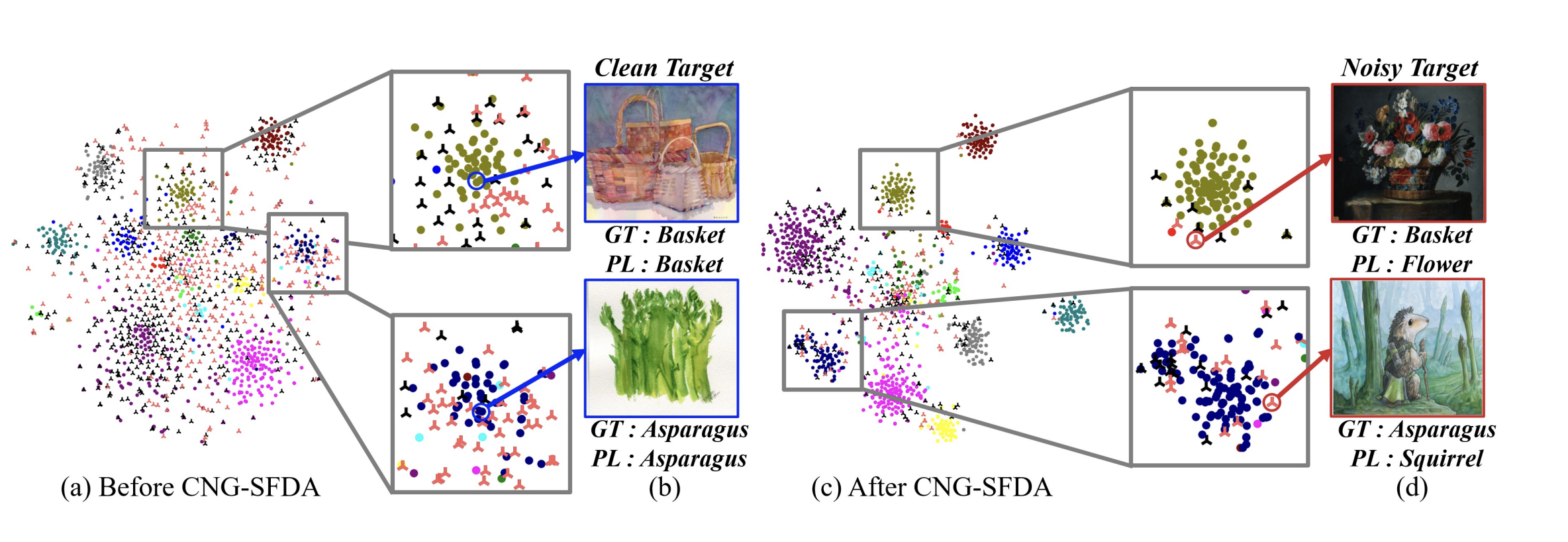
CNG-SFDA: Clean-and-Noisy Region Guided Online-Offline Source-Free Domain Adaptation
ACCV 2024
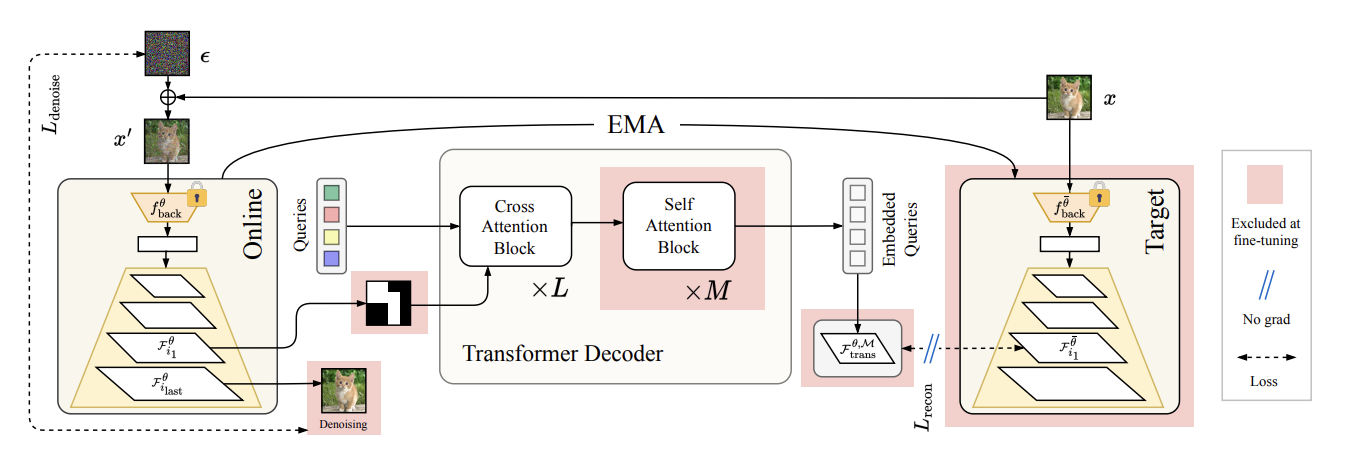
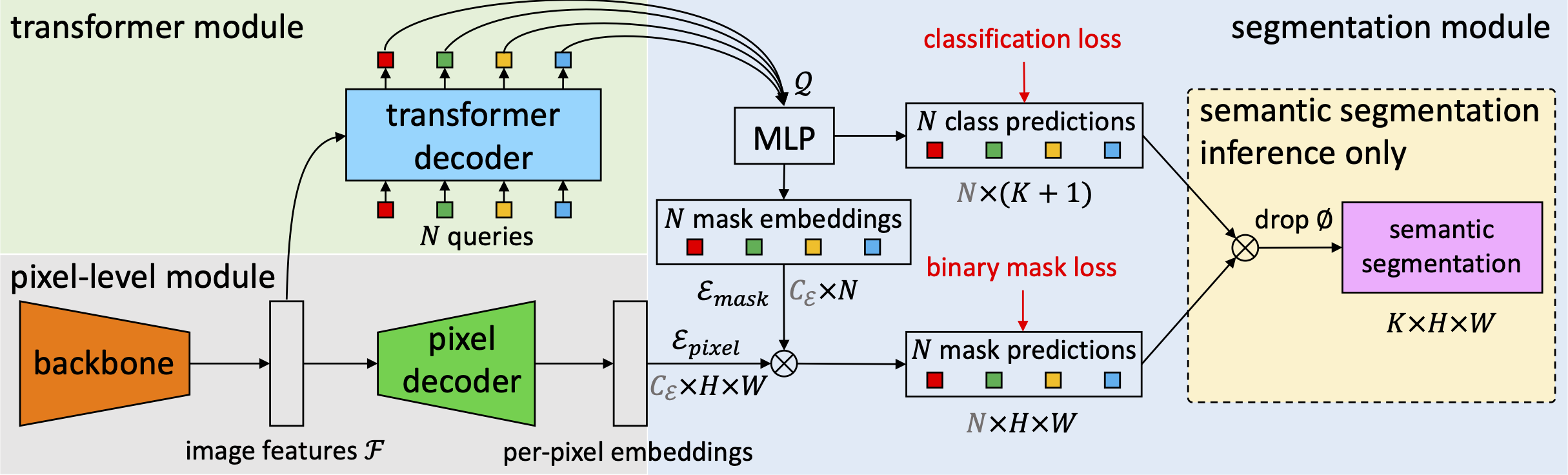
Joint-Embedding Predictive Architecture for Self-Supervised Learning of Mask Classification Architecture
arXiv, 2024
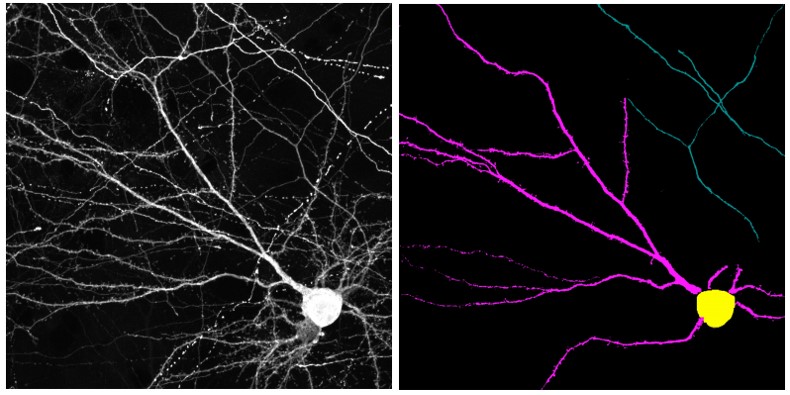
Neuron segmentation using incomplete and noisy labels via adaptive learning with structure priors
ISBI 2021
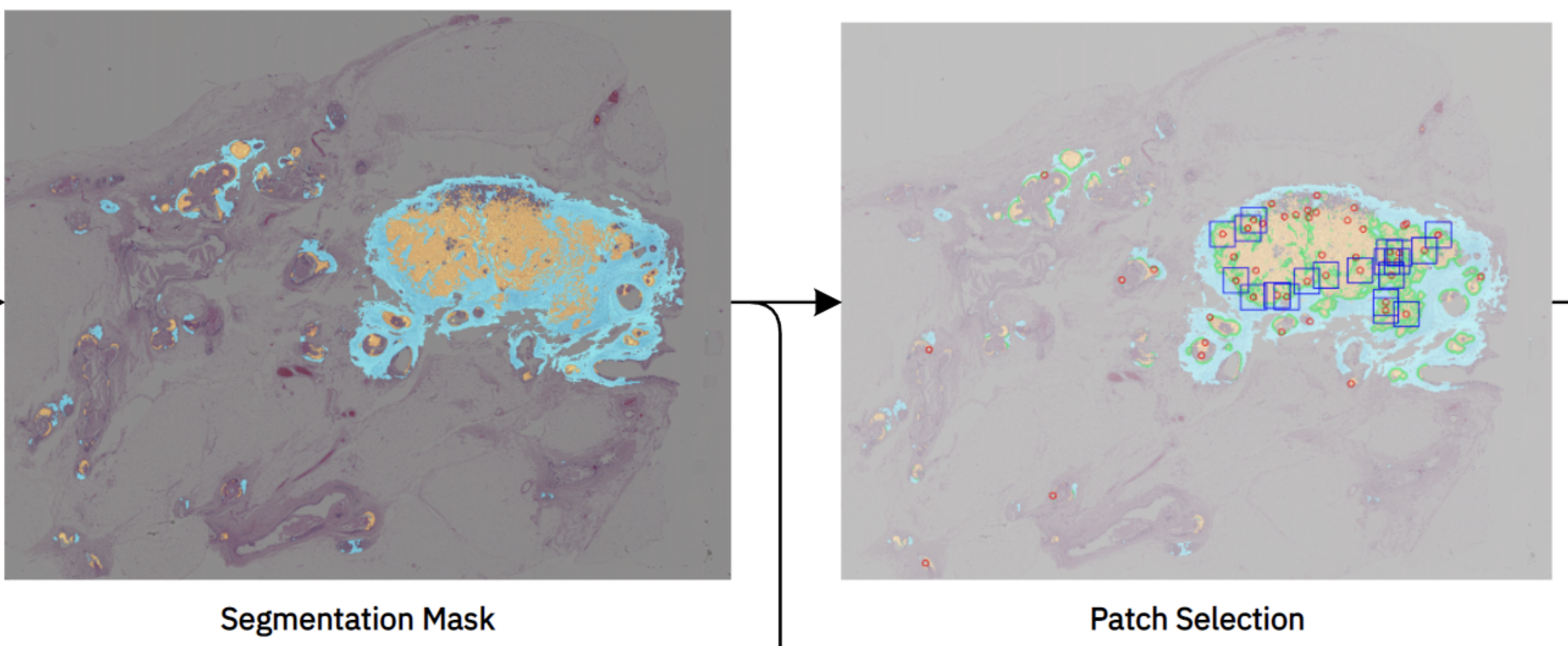
Tumor-infiltrating lymphocytes in breast cancer through artificial intelligence: biomarker analysis from the results of the TIGER challenge
medRxiv, 2025
데이터 기반 동적 필터링이 포인트 클라우드 객체 증분 학습에 미치는 영향도 분석
한국정보과학회 학술발표논문집, 2025
Development of a KFDA-certified Deep Learning Algorithm for Quantitative Analysis of Ki-67 Immunohistochemical Stains
대한병리학회 (Domestic Conference)
Patents
- Method for analyzing medical image (Application number: 1020210139898)
- Method For Analyzing Medical Image based on deep learning (Application number: 1020210139897)
- Brain Neural Network Structure Image Processing System, Brain Neural Network Structure Image Processing Method, and a computer-readable storage medium (Registration number: 1020210139898)
Expertise & Tools
Awards & Competitions
- 🥇 TIGER Challenge - 1st PlaceVUNO
- 🥇 HealthHub Datathon - 1st Place2020
- 🏆 Video Recognition: Google - Isolated Sign Language Recognition
- 🥇 Instance Segmentation: HealthHub Datathon Track B - 1st Place2020
- 🎯 Object Detection: Lesion Detection AI Competition Code Link
- 🏅 Tabular Classification: Autonomous Driving Sensor - Top 8%
- Inje Creative Comprehensive Design Contest🥇 Gold
- 2017 Engineering Festival Competition🥉 Bronze
- Good Capstone Design Contest🏅 Excellence
Recent Posts
[PaperReview] UCDR-Adapter: Exploring Adaptation of Pre-Trained Vision-Language Models for Universal Cross-Domain Retrieval
Paper: WACV 2025 paper PDF: OpenAccess PDF
[PaperReview] MaPLe: Multi-modal Prompt Learning
Paper: MaPLe: Multi-modal Prompt Learning PDF: arXiv PDF Code: GitHub
[PaperReview] DePro: Domain Ensemble using Decoupled Prompts for Universal Cross-Domain Retrieval
Paper: SIGIR 2025, DePro: Domain Ensemble using Decoupled Prompts for Universal Cross-Domain Retrieval PDF: paper...
[PaperReview] ProS: Prompting-to-Simulate Generalized Knowledge for Universal Cross-Domain Retrieval
Paper: CVPR 2024 paper OpenAccess: CVF OpenAccess
[ROS2] 01: Introduction (ROS2 소개)
ROS2 (Robot Operating System 2) 학습 시리즈 ROS2에 대한 기본적인 내용에 대해서 정리하고 설명하고자 한다....
[PaperReview] Semantic Feature Learning for Universal Unsupervised Cross-Domain Retrieval
Wang, Lixu, Xinyu Du, and Qi Zhu. “Semantic feature learning for universal unsupervised cross-domain retrieval.”...
[PaperReview] Unsupervised Cross-domain Image Retrieval via Prototypical Optimal Transport
Li, Bin, et al. “Unsupervised cross-domain image retrieval via prototypical optimal transport.” Proceedings of the...
[PaperReview] Noise Mitigation for Unsupervised Cross-Domain Image Retrieval
Liu, Jiayang, et al. “Noise Mitigation for Unsupervised Cross-Domain Image Retrieval.” 2025 IEEE International Conference...
[PaperReview] Feature Representation Learning for Unsupervised Cross-domain Image Retrieval
Authors: Conghui Hu, Gim Hee Lee (National University of Singapore) Conference: ECCV 2022 arXiv: 2207.09721...
[PaperReview] Unsupervised Feature Representation Learning for Domain-Generalized Cross-Domain Image Retrieval
Hu, Conghui, Can Zhang, and Gim Hee Lee. “Unsupervised feature representation learning for domain-generalized cross-domain...
[PaperReview] Correspondence-free Domain Alignment for Unsupervised Cross-domain Image Retrieval
Wang, Xu, et al. “Correspondence-free domain alignment for unsupervised cross-domain image retrieval.” Proceedings of the...
[CS231A] Lecture 10: Optimal Estimation (최적 추정)
Stanford CS231A: Computer Vision, From 3D Reconstruction to Recognition 이 포스트는 Stanford CS231A 강의의 열...
[CS231A] Lecture 09: Optical and Scene Flow (광학 및 장면 흐름)
Stanford CS231A: Computer Vision, From 3D Reconstruction to Recognition 이 포스트는 Stanford CS231A 강의의 아홉...
[CS231A] Lecture 08: Monocular Depth Estimation (단안 깊이 추정)
Stanford CS231A: Computer Vision, From 3D Reconstruction to Recognition 이 포스트는 Stanford CS231A 강의의 여덟...
[CS231A] Lecture 07: Representation Learning (표현 학습)
Stanford CS231A: Computer Vision, From 3D Reconstruction to Recognition 이 포스트는 Stanford CS231A 강의의 일곱...
[CS231A] Lecture 06: Fitting and Matching (피팅 및 매칭)
Stanford CS231A: Computer Vision, From 3D Reconstruction to Recognition 이 포스트는 Stanford CS231A 강의의 여섯...
[CS231A] Lecture 05: Active and Volumetric Stereo (능동 및 볼륨 스테레오)
Stanford CS231A: Computer Vision, From 3D Reconstruction to Recognition 이 포스트는 Stanford CS231A 강의의 다섯...
[CS231A] Lecture 04: Stereo Systems (스테레오 시스템)
Stanford CS231A: Computer Vision, From 3D Reconstruction to Recognition 이 포스트는 Stanford CS231A 강의의 네...
[CS231A] Lecture 03: Epipolar Geometry (에피폴라 기하학)
Stanford CS231A: Computer Vision, From 3D Reconstruction to Recognition 이 포스트는 Stanford CS231A 강의의 세...
[CS231A] Lecture 02: Single View Metrology (단일 뷰 측정학)
Stanford CS231A: Computer Vision, From 3D Reconstruction to Recognition 이 포스트는 Stanford CS231A 강의의 두...
[CS231A] Lecture 01: Camera Models (카메라 모델)
Stanford CS231A: Computer Vision, From 3D Reconstruction to Recognition 이 포스트는 Stanford CS231A 강의의 첫...
[CS231A] Lecture 02: Single View Metrology (단일 뷰 측정학)
Stanford CS231A: Computer Vision, From 3D Reconstruction to Recognition 이 포스트는 Stanford CS231A 강의의 02번째...
3D Vision Tutorial
이 포스트는 3D Vision에 대한 튜토리얼 비디오를 포함합니다.
Image Transformation and Warping
이미지 등록부터 창의적 효과까지 다양한 응용을 가능하게 하는 기하학적 이미지 조작의 필수 기법입니다.
Image Processing Basics
컴퓨터 비전과 디지털 이미지 분석의 기본이 되는 이미지 처리의 핵심 개념과 방법을 소개합니다.
Advanced Image Filtering Techniques
고급 이미지 필터링 기법을 통해 정교한 이미지 향상 및 분석 기능을 제공합니다.
Vision Transformer Primer
CNN을 대체하는 기본 백본으로 자리 잡은 ViT의 핵심 파이프라인을 정리합니다.
Deep Learning Systems for Reliable Vision
연구용 prototype을 실제 서비스로 전환할 때 고려해야 할 데이터 파이프라인, 학습 인프라, 배포 전략을 정리합니다....
Physically Based Rendering Cheat Sheet
현대 실시간/오프라인 렌더러의 기본 규칙인 PBR의 핵심 수식과 파라미터를 요약합니다.
3D Geometry Fundamentals for Vision
3D 비전 파이프라인에서 필요한 카메라 모델, 좌표계, 변환 행렬의 기초 공식을 모았습니다.
[PaperReview] SAM 3D: 3Dfy Anything in Images
SAM 3D는 자연 이미지 한 장과 객체 마스크만으로 3D geometry, texture, layout을 한 번에 추출하는...